Other Parts Discussed in Thread: SYSCONFIG
I have a multi-core FreeRTOS project, with R5_0-0 initialising GPIO Bank 0 with a HW interrupt. I also have a collection of variables stored in shared memory, which are successfully initialised across all cores at startup.
The GPIO bank interrupt function identifies which pin was triggered, and then records the state to a variable in shared memory.
I've got a relatively comprehensive multi-core application extensively sharing memory, communicating via IPC to synchronise operations, etc. and it mostly works fine. However, I have two problems that I suspect are related and I'm hoping someone can help shed some light on:
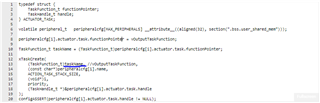
1. If I use IpcNotify_syncAll after initialising shared memory across the cores, two of my cores/apps crash with a HWI assert issue when the first task tries to init. I don't know why, as the IPC Sync part seems to work fine, and I'm not aware of any other HWI's on those cores. I've been working around this by not syncing the cores at all and realising that if I load each core one-by-one with a few seconds in between then each will successfully initialise its tasks and operate as expected. But, of course, that's not deployable.
2. There's one exception to everything working given the workaround - the GPIO bank interrupt works fine when I load R5_0-0 before loading any of the other cores or on it's own. I trigger the switch, the interrupt happens, and the state of the input is stored to a variable in the shared memory space (not really shared, yet, as it's the only core running). As soon as I load any other core, the 'new' core successfully initialises its shared memory (and overwrites the data for R5_0-0 as is to be expected, with the R5_0-0 console showing this), but then the GPIO bank interrupt stops working. It's almost like the GPIO pin configuration set by R5_0-0 is reset or altered by the other core, but I can't imagine why that would be given Sysconfig doesn't show any conflicts.
I had the same problem with 05.00.24 also.
To combat (1) I'm thinking of implementing an inelegant solution attempt to either make each core wait a given amount of seconds before creating it's tasks, so that only one core is doing that at a time, or using a chain of IPC Notify messages so each core will wait for the previous core to create it's tasks before creating it's own - but this seems wasteful and I'm no closer to understanding why creating tasks on separate cores in parallel are creating such a problem.
For (2) I'm out of ideas. I've been battling this for a few weeks, and I suspect it has to be something related to (1), since I can't think of any other aspect to help debug.
If anyone has any ideas, I'd love to hear them. Thanks in advance.