Hello,
I changed our RPMessage-Ipc-Implementation from using a notify and then reading out the RPMessage-Buffer in a task context to an interrupt driven implementation which reads out the ipc-buffer as soon as the callback is called.
But here I faced two problems.
1.
when using a RPMessage_send from both cores at nearly the same time window with a timeout of 0 it happens that one of the two cores (seems to be related which one is started first) returns with a timeout. This comes from the function RPMessage_vringGetEmptyTxBuf which returns SystemP_FAILURE, which is the internal branch of /* There's nothing available */. While the other one can send normally. If I raise the timeout to ten I can at least handle the first packages but then this happens at a later point:
2.
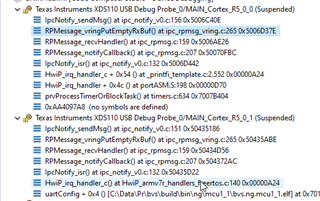
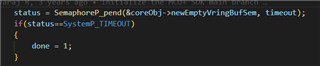
This seems to be really strange, when looking into the function it hangs inside a loop which it would never return following the logic since the mailboxIsFull stays 1 when both cores stay in this loop. And this happens inside working on the interrupt that is issued because the other core did send a telegram: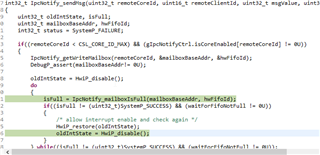
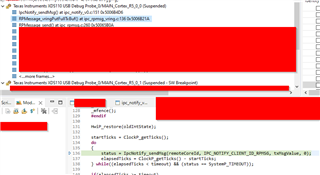
Those are the variables in this case for RPMessage: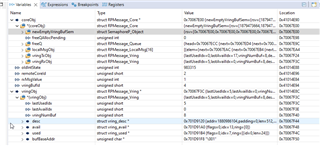
and for IpcNotify: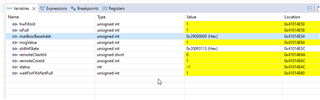
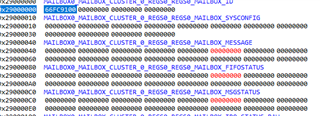
and a register snippet for the two cores for the mailbox-registers: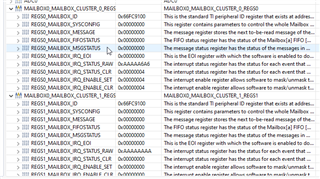
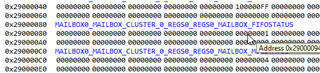
The MAILBOX-registers also show some more values in memory-view, not sure if this is important, since there are some bits set, not shown in the register-view: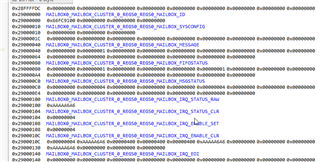
This seems to be a deadlock-situation that happens when both cores send messages simultaeneously.
I changed to this implementation coming from the task-context-based-implementation, because it happened that one core was busy with other stuff while the other core already filled the vring-buffers and could not send anymore. I thought that may be a valid solution then but then those problems occured.
I will snip down to the sequences since there is some of our code around. Keep in mind we initialize the needed params with valid values in our own driver-implementation:
IpcNotify_Params notifyParams;
int32_t status;
/* initialize parameters to default */
IpcNotify_Params_init(¬ifyParams);
/* specify the core on which this API is called */
notifyParams.selfCoreId = OWN_CORE_ID;
notifyParams.numCores = IPC_CORES - 1;
RPMessage_Params rpmsgParams;
/* initialize parameters to default */
RPMessage_Params_init(&rpmsgParams);
/* initialize the IPC Notify module */
status = IpcNotify_init(¬ifyParams);
rpmsgParams.vringSize = IPC_RPMESSAGE_VRING_SIZE;
rpmsgParams.vringNumBuf = IPC_RPMESSAGE_NUM_VRING_BUF;
rpmsgParams.vringMsgSize = IPC_RPMESSAGE_MAX_VRING_BUF_SIZE;
/* initialize the IPC RP Message module */
status = RPMessage_init(&rpmsgParams);
IpcNotify_syncAll(SystemP_WAIT_FOREVER);
/* create RPParams afterwards since it would overwrite the notify-sanc-callback */
RPMessage_CreateParams createParams;
RPMessage_CreateParams_init(&createParams);
createParams.recvCallback = &newSysMessageCbStatic;
createParams.recvCallbackArgs = reinterpret_cast<void*>(this);
createParams.localEndPt = SYSTEM_CHANNEL_ENDPT_ID;
RPMessage_construct(&systemChannelMsgObject_, &createParams);
// at other points in the program on both cores:
RPMessage_send(ptrToData, dataSize, TARGET_CORE_ID, SYSTEM_CHANNEL_ENDPT_ID, SYSTEM_CHANNEL_ENDPT_ID, 0) == SystemP_SUCCESS)
// the callback
void IpcDriver::newSysMessageCbStatic(RPMessage_Object *obj, void *arg, void *data, uint16_t dataLen, uint16_t remoteCoreId, uint16_t remoteEndPt)
{
reinterpret_cast<IpcDriver*>(arg)->newSysMessageCb(data);
}
The callback gets called on the other core! So In my understanding it should use the packet, do its work inside the callback and then give the memory inside the buffer free again.
So I wouldn't see any problem having a whole interrupt-based solution since even if multiple cores are sending messages at the same time the RPMessage-implementation. But here it seems
we also ensured the interrupt-stacks have enough size:

Edit: Update:
I also tried inifite-timeout values the behaviour stays the same like in 2.
I also noticed that a warm reset does not reset the Ipc-related stuff correctly. I got this "hanging"-bug also at the IpcNotify_syncAll-function-call after a CPU-reset and load again of the images in CCS. Is this preventable? A clean reset would be a nice feature.
Setup:
We have a region in the linker defined for the IPC-shared memory. It start at 0x701D0000 in our case (IPC starts at 0x701D8000). The MPU is set accordingly to not cached but shared. We have our own IpcDriver but are using the RPMessage. We have ensured that the VRING is aallocated accordingly to what SysCfg would normally so. Without going too deep into detail: The whole situation once worked before without using the direct callbacks but the notify and then getting the packet in a task context. It first appeared as soon as I changed it to a direct callback.
Best regards
Felix