Part Number: LP-AM243
I'm having a problem with xTaskNotifyFromISR and xTaskNotifyWait.
I have had a collection of them working for a long time and not sure what's changed. Recently one stopped working, and as of today, I can't get any of them to work.
I have an IPC interrupt function as follows:
void ipcCommandHandler(uint32_t remoteCoreId, uint16_t localClientId, uint32_t msgValue, void *args)
{
uint32_t i = (uint32_t)args;
int32_t status;
gIpcCallCount++;
// Send the IPC Notify message value to the corresponding task using Task Notify
BaseType_t xHigherPriorityTaskWoken = pdFALSE;
xTaskNotifyFromISR(systemcfg[i].task.handle, (uint32_t)msgValue, eSetValueWithOverwrite, &xHigherPriorityTaskWoken);
portYIELD_FROM_ISR(xHigherPriorityTaskWoken);
/* Echo the message back as an ack. Server is waiting. */
status = IpcNotify_sendMsg(remoteCoreId, localClientId, (uint32_t)msgValue, 1);
DebugP_assert(status == SystemP_SUCCESS);
gIpcCallCount++;
return;
}
And in my tasks, I have the following:
uint32_t message;
int32_t status;
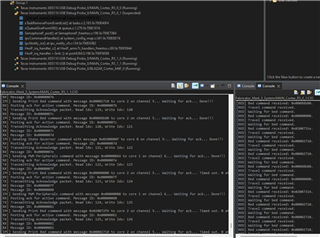
DebugP_log("[%s] Waiting to receive a command.\r\n", systemcfg[sysIdx].name);
status = xTaskNotifyWait(0, 0, &message, portMAX_DELAY);
DebugP_log("[%s] Notify status: %d.\r\n", systemcfg[sysIdx].name, status);
DebugP_assert(status == pdTRUE);
The problem is when I trigger the IPC Notify interrupt, I can use the gIpcCallCount variable inside the ISR to confirm it's starting to execute, but then two things happen:
gIpcCallCountonly gets a value of 1, meaning the second increment after the xTaskNotify isn't reached- The task being notified seems to crash - ROV shows that before the event the task is blocked, but after it's not there at all
Any idea why this might be happening? This has me stumped.