Part Number: TMS570LS3137
Other Parts Discussed in Thread: HALCOGEN
Tool/software:
Hi,
I'm developing safety project for avionic and I'm using TMS570LS3137. My IDE is CCS. I tried ECC features on the evaluation board. I have been tested checking RAM ECC function. It worked and I observed in the debug mode.
Now, I want to try flash ECC. First of all, I want to specified that I'm using HALCOGEN and Flash ECC is enabled on halcogen. than I observed that sys_startup.c has been called checkFlashECC() function. There is no problem to here.
but I cannot be able to understand how can change any bit on the flash. I think that I need change any bit in the flash memory and ECC flash checker should be detected bit changing and run the error Interrupt. Please correct me for this scenario.
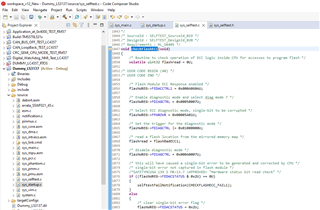
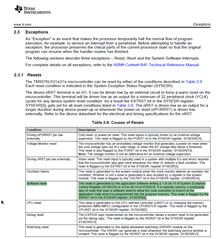
you can view below checkFlashECC() function.
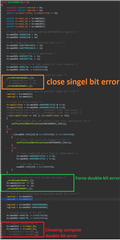
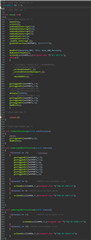
void checkFlashECC(void)
{
/* Routine to check operation of ECC logic inside CPU for accesses to program flash */
volatile uint32 flashread = 0U;
/* USER CODE BEGIN (40) */
/* USER CODE END */
/* Flash Module ECC Response enabled */
flashWREG->FEDACCTRL1 = 0x000A060AU;
_coreEnableFlashEcc_();
/* Enable diagnostic mode and select diag mode 7 */
flashWREG->FDIAGCTRL = 0x00050007U;
/* Select ECC diagnostic mode, single-bit to be corrupted */
flashWREG->FPAROVR = 0x00005A01U;
/* Set the trigger for the diagnostic mode */
flashWREG->FDIAGCTRL |= 0x01000000U;
/* read a flash location from the mirrored memory map */
flashread = flashBadECC1;
/* disable diagnostic mode */
flashWREG->FDIAGCTRL = 0x000A0007U;
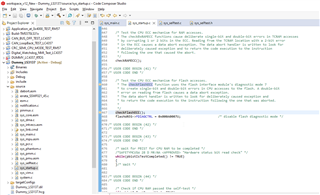
/* this will have caused a single-bit error to be generated and corrected by CPU */
/* single-bit error not captured in flash module */
/*SAFETYMCUSW 139 S MR:13.7 <APPROVED> "Hardware status bit read check" */
if ((flashWREG->FEDACSTATUS & 0x2U) == 0U)
{
selftestFailNotification(CHECKFLASHECC_FAIL1);
}
else
{
/* clear single-bit error flag */
flashWREG->FEDACSTATUS = 0x2U; // By giving a value of 2 to that register, how do we clear the bit?
/* clear ESM flag */
esmREG->SR1[0U] = 0x40U;
/* Enable diagnostic mode and select diag mode 7 */
flashWREG->FDIAGCTRL = 0x00050007U;
/* Select ECC diagnostic mode, two bits of ECC to be corrupted */
flashWREG->FPAROVR = 0x00005A03U;
/* Set the trigger for the diagnostic mode */
flashWREG->FDIAGCTRL |= 0x01000000U;
/* read from flash location from mirrored memory map this will cause a data abort */
flashread = flashBadECC2;
/* Read FUNCERRADD register */
flashread = flashWREG->FUNCERRADD;
/* disable diagnostic mode */
flashWREG->FDIAGCTRL = 0x000A0007U;
}
/* USER CODE BEGIN (41) */
/* USER CODE END */
}
Do I need extra function or code for the checking flash ecc? this function is running in the sys_starup.c so it run before the main but I called this function in the infinity loop. but not any changing so, not working.
Also, Can you advice test code for flashECC for that MCU(F021)?