Part Number: TMS570LC4357-EP
Tool/software:
Hi TI team,
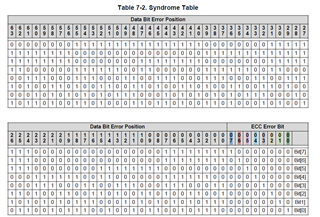
I’m currently working with the TMS570 microcontroller and have been studying its ECC (Error Correcting Code) mechanism, specifically the SECDED (Single Error Correction, Double Error Detection) implementation for SRAM. I have a few questions regarding the handling of ECC code errors, particularly in cases where the ECC code itself is affected.
My specific questions are:
-
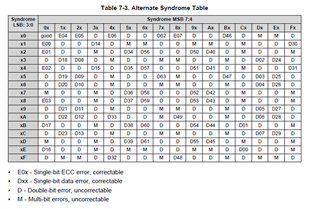
If a single-bit error occurs in the ECC code itself (as opposed to the data), how does the SECDED mechanism handle this in terms of both error detection and correction?
- Could the ECC mechanism potentially detect this as both a single-bit error and a multi-bit error simultaneously?
- From a correction standpoint, is there a risk that the mechanism might incorrectly correct the data based on a faulty ECC code, while leaving the ECC code unchanged? This is a major concern in my application.
-
If such a scenario (i.e., erroneous correction of data due to a faulty ECC code) is possible, are there any strategies or mechanisms available to enhance the reliability of the ECC code itself?
- For example, are there recommended methods or features within the TMS570 architecture to further protect the ECC code from bit errors?
-
Lastly, does TMS570 implement any kind of redundancy for the ECC code (e.g., storing multiple copies of the ECC code and using majority voting mechanisms), or is it limited to a single copy of the ECC code for each 64-bit data word?
Any clarification or recommendations on improving the ECC code's reliability would be greatly appreciated!
Best regards,
Hanson