Part Number: AM2431
Other Parts Discussed in Thread: SYSCONFIG
Tool/software:
Hi all TI experts,
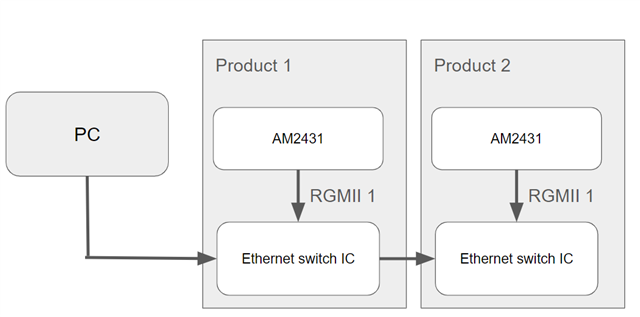
According to the link above, when testing with iperf using the AM243-LP, with a data length of 1470 bytes, the best case RX speed can reach up to 110 Mbps. Does this mean that although the AM243 supports gigabit Ethernet speeds, the MCU itself cannot process gigabit data within one second?
Best regards,
Larry