Other Parts Discussed in Thread: TMS320F28388D, , AM263P4, C2000WARE
Tool/software:
Hello,
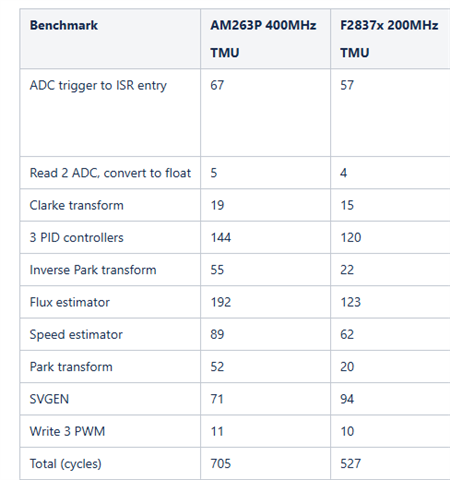
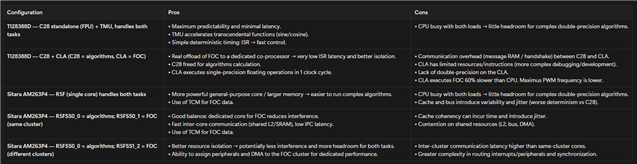
I would like to compare the performance of TMS320F28388D and Sitara AM2634 for motor control applications.
The goal is to understand which device is better suited to:
-
Execute a Field-Oriented Control algorithm reliably in real time.
-
Still leave enough CPU headroom to run an additional complex algorithm in double precision.
I am looking for hints and best practices on how to set up such a benchmark.
-
Which parameters are most relevant to measure?
-
What kind of methodology would you recommend?
-
Are there any TI reference materials, existing benchmarks, or example projects that could help?
Any guidance from the community or TI experts would be very helpful.
Thanks in advance!