


Part Number: TMS570LC4357
Team,
Can you please help with the below questions.
Thanks in advance,
Anthony
TMS570LC4357 is connected to NVRAM, With EMIF as asynchronous memory with a 16-bit word width.
About Turnaround period:
-Under what conditions the turnaround is inserted?
Only when switching between read and write / write and read, or also between two read / two write accesses?
Is there a difference between a 32-bit memory access (which then results in two 16-bit EMIF accesses) and two 16-bit memory accesses placed directly one after the other?
-Where is the turnaround period is inserted?
On TRM SPNU563 page 814 it reads as if it is inserted before an EMIF access.
However, Figure 21-32 on page 845 shows it after an access.
-It is also unclear which register values lead to which setup, strobe, hold and turnaround times.
On TRM SPNU563 page 812, the term ‘minus one cycle’ is used in each case, so I would assume that a register value of 0, for example, leads to a setup time of one EMIF cycle.
However, the information and diagrams on pages 812 and 845 partly contradict this theory.
The turnaround period is particularly unclear to me in this context.
-We have also carried out tests with the EMIF interface, which have led to further questions.
The interface was operated at 37.5 MHz and the associated configuration register (CE2CFG) was set to the value 0x04142111U.
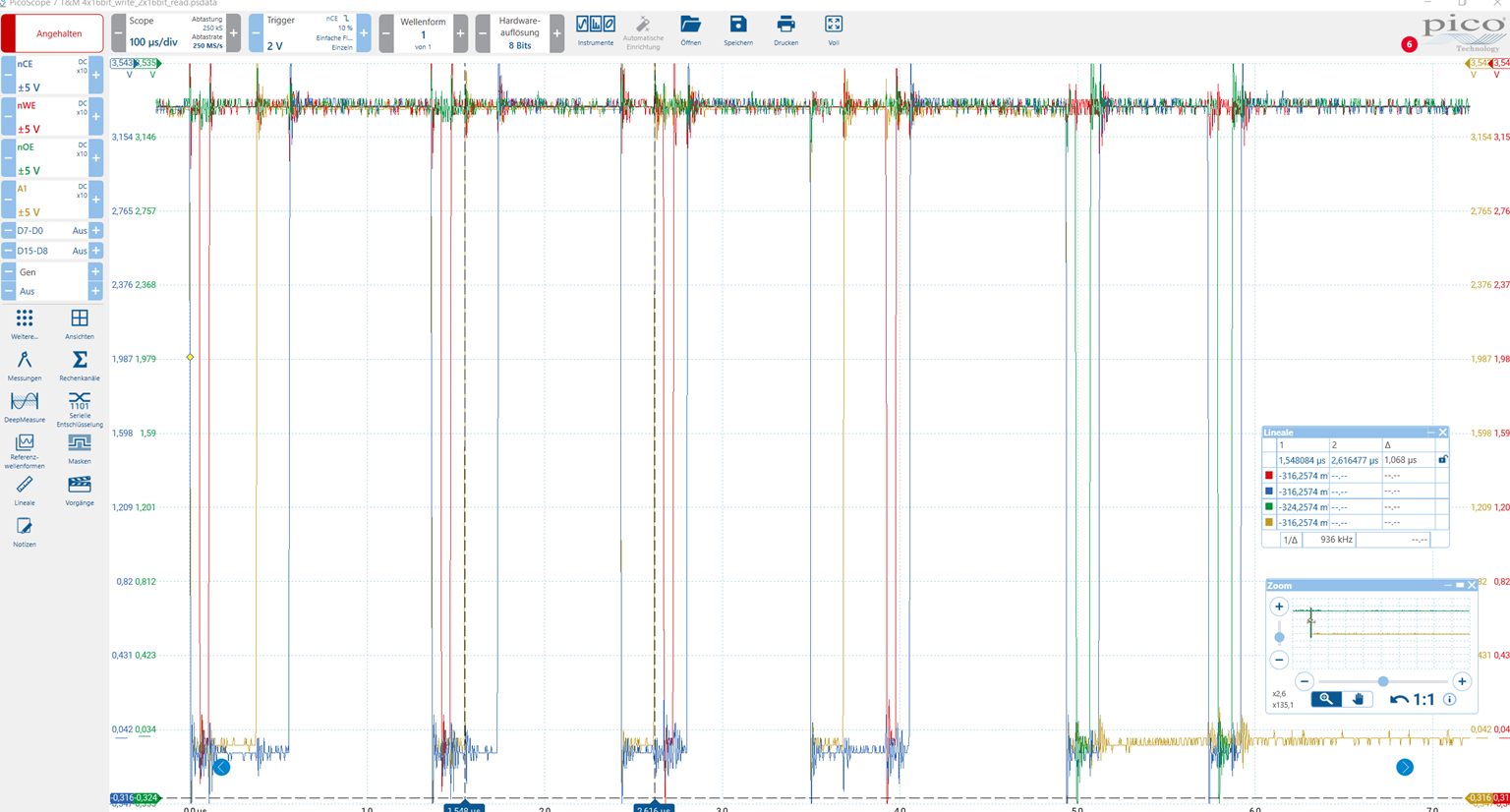
The following recording shows four 16-bit write accesses followed by two 16-bit read accesses:
The following code was executed for this: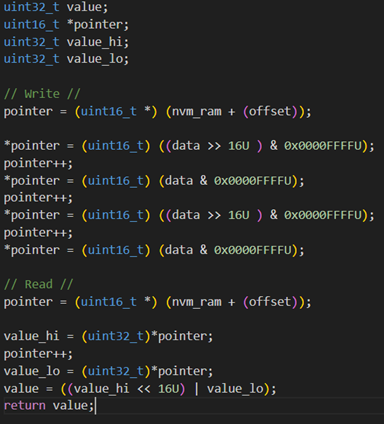
The two read accesses look as expected, but the four write accesses do not.
It is noticeable that the chip select is pulled much earlier or remains pulled much longer than necessary.
The address bit A1 also does not always behave as described in the TRM.
Furthermore, the extremely long time between individual accesses is noticeable, varying between 613 ns and 1.068 µS (see rulers).
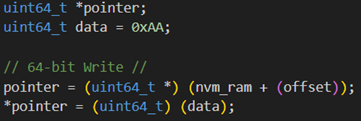
Another test was carried out, this time with a 64-bit write access: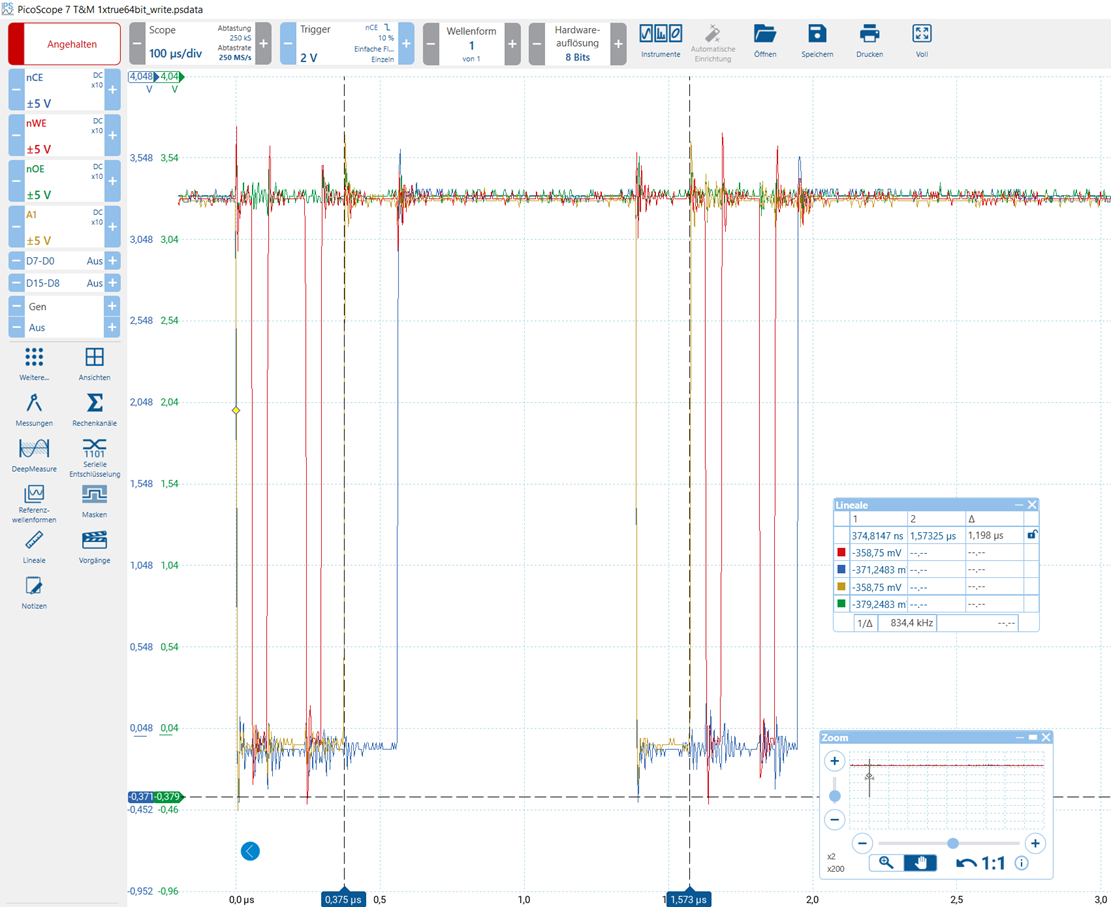
As expected for a 32-bit architecture, this access was divided into two 32-bit accesses.
Each 32-bit access appears to consist of two 16-bit accesses directly strung together.
However, this test again shows a very long time (1.198 µS) between the two 32-bit accesses.
The questions that arise:
-How can the behaviour of the chip select during write accesses be explained, and can this be reconciled with the information from the TRM?
-Is there a way to shorten the long wait time between individual 16/32-bit accesses in order to achieve a higher effective data rate?

