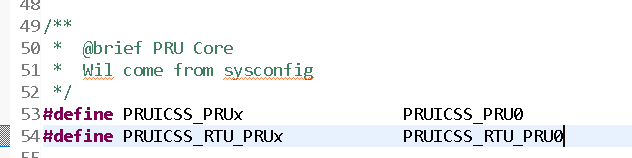
Part Number: AM2431
Hi experts,
When using the PRU for reading and writing I/O, we noticed a potential delay. Please help confirm whether this issue exists and if there are any methods to resolve it.
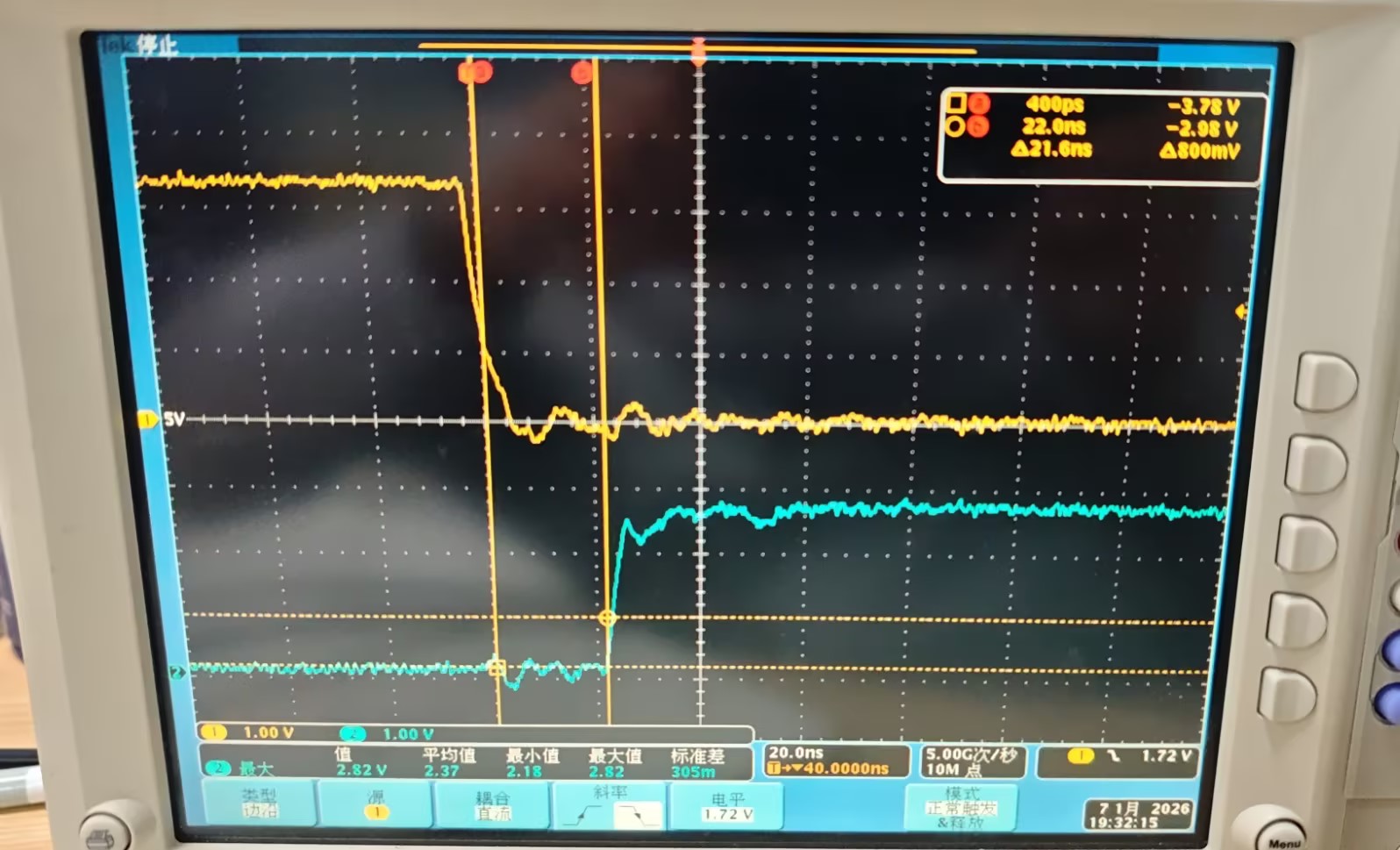
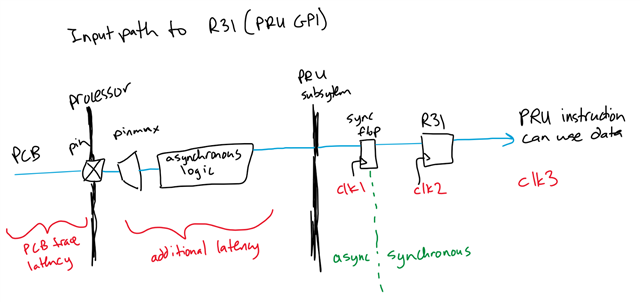
Using the PRU as an SPI slave, after detecting the falling edge of CS, we pull SDO high. The code only consists of two instructions, but the SDO level rises 21 ns later. Current testing indicates that the detection of the CS pin is delayed, as if there is a latency in the GPIO input pin.
Below are the test code and waveforms.