Part Number: AM2434
Other Parts Discussed in Thread: TMDS243EVM, AM2612, , LP-AM261, AM6442, SYSCONFIG, MATHLIB
Hi support team,
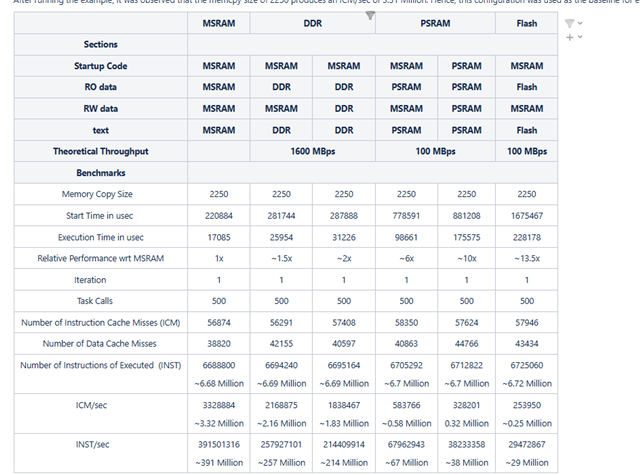
I am evaluating both AM2612 and AM2434. With the same code used for benchmarking, and placing the code, data and stack in the main memory (OCSRAM or MSRAM), with cache enabled, MPU correctly configured, and the clocks as provided in the example demos (R5f @500MHz on AM2612 and 800MHZ on AM2434 on TMDS243EVM board), I am experiencing similar results on both targets, while I expected a better performance with AM2434 which has a higher clock speed for R5F core.
I am trying to find the differences between the two setups: I have the same code, same compiler, same compiler options (-O2), same MPU configuration, different R5 clocks, and the only factor I could think is the MSRAM/OCSRAM clock frequency.
I found in the AM2612 reference manual that the OCSRAM is clocked at 200MHz (see below), but I can not find any information about the MSRAM in AM2434 (as refered in this post: https://e2e.ti.com/support/microcontrollers/arm-based-microcontrollers-group/arm-based-microcontrollers/f/arm-based-microcontrollers-forum/1326676/mcu-plus-sdk-am243x-sram-clock?tisearch=e2e-sitesearch&keymatch=am2434%2525252520sram%2525252520clock):

I am just trying to figure out what leads to this difference, so if you could at least give me the MSRAM frequency in AM2434, that would be great. In my project, the AM24x_GP_EVM.gel script is used to initialize the CPU clocks for the board (with DDR).
Best regards