


Part Number: AM2612
Dear Experts,
I am working on IPC communication between Core 1 and Core 0 of my AM261x-LP. I modified the example l2_enet_switch, in a way that Core 1 receive the packet and then send the packet to the Core 0. The communication works like this:
- Ethernet pkt is received from Core 1
- ISR is generated and semaphore is posted
- RX Task run and write the dequeued packet inside shared memory between Core 0 and Core 1
- Core 1 notify Core 0 (IPC Notify mechanism) that a new packet is received
- Core 0 wakes up and copy the packet from the shared ram inside its own RAM
Every access of shared ram is protected by a spinlock. I read the post on shared ram, and my memory map is like this:
- OCRAM Bank 0: SBL + Core 0
- OCRAM Bank 1: CPPI desc + Core 1 (included the Enet DMA Packet Pool)
- OCRAM Bank 2: Shared Memory between Core 1 and Core 2. It is just a 2 KB region (for 1 full Etheret Packet), where the packet is copied to / from. The MPU is configured like this, both for Cores
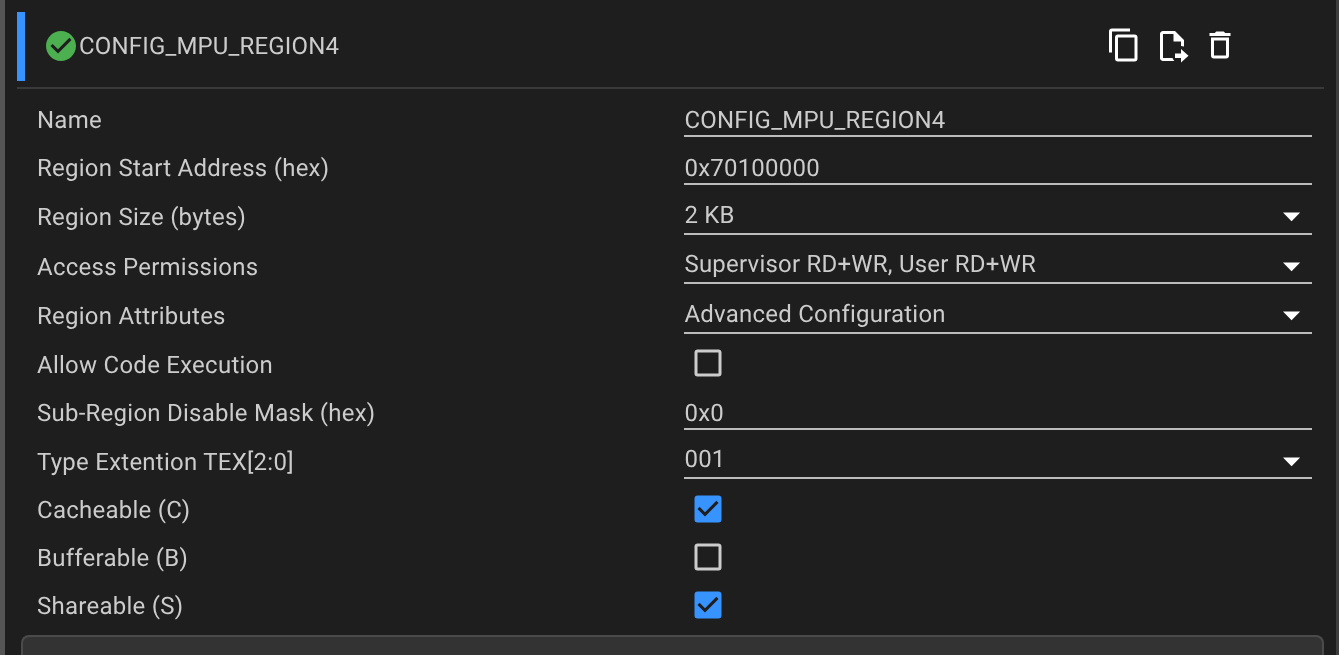
The problem arise when I perform a memcpy in Core 0 and I am not managing to explain why: the memcpy takes exactly 85 us, against the 3.75 us of the Core 1.
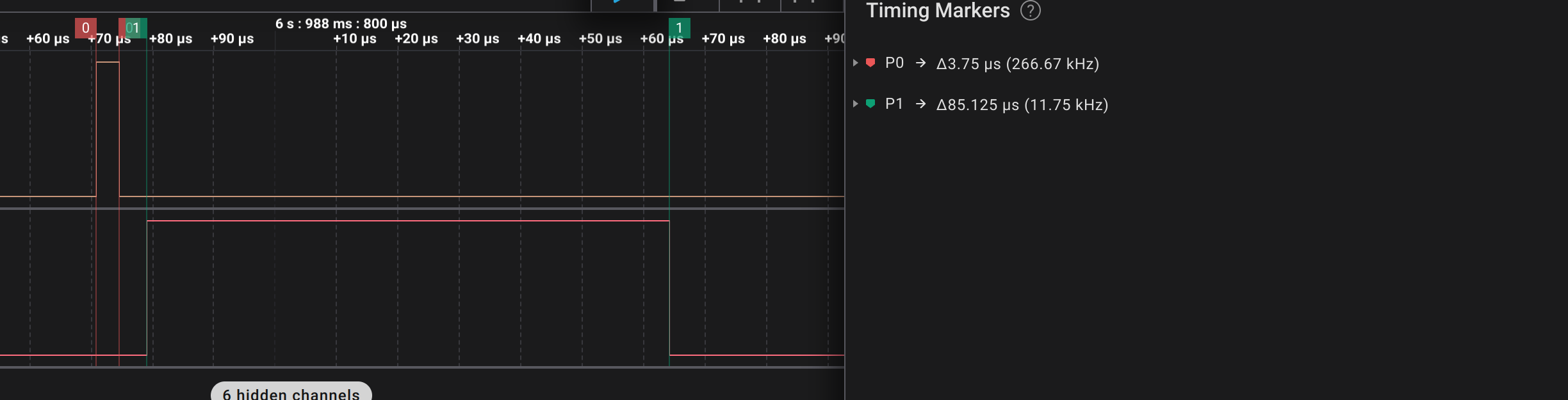
The code snippet are:
namespace Core0
{
static EthFrame internalFrame;
// Called inside the IPC callback
static void ethTakePkt()
{
spinlock_lock(SPINLOCK_0);
CacheP_inv((void*)ðPkt, sizeof(ethPkt), CacheP_TYPE_L1D);
hal_gpio_on(DEBUG_PIN_0);
memcpy((void*)&internalFrame, (void*)ðPkt, sizeof(EthFrame));
hal_gpio_off(DEBUG_PIN_0);
spinlock_unlock(SPINLOCK_0);
return;
}
}
namespace Core 1
{
// Called inside RX Task
static void copyFrame(EthFrame *frame)
{
spinlock_lock(SPINLOCK_0);
hal_gpio_on(DEBUG_PIN_1);
memcpy((void*)ðPkt, (void*) frame, sizeof(EthFrame));
hal_gpio_off(DEBUG_PIN_1);
CacheP_wbInv((void*)ðPkt, sizeof(EthFrame), CacheP_TYPE_L1D);
spinlock_unlock(SPINLOCK_0);
}
}
namespace Common
{
volatile EthFrame ethPkt __attribute__((aligned(128), section(".bss.eth_pkt")));
}I inspect the generated code and confirm that compiler is not optimizing memcpy by deleting it.
Any idea why Core 0 takes much long to copy data?
