Part Number: AM263P4
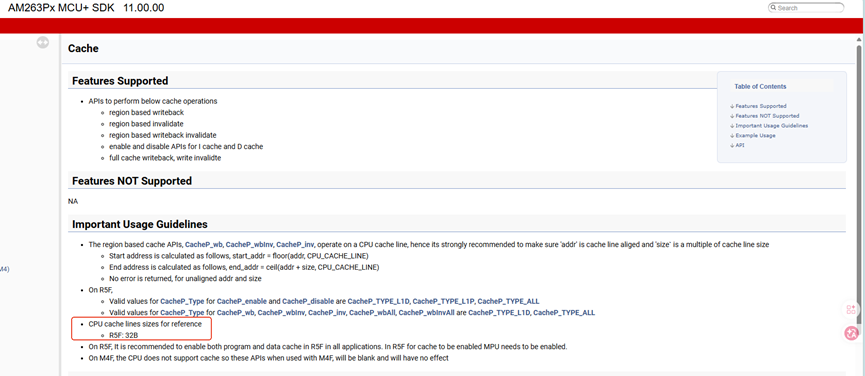
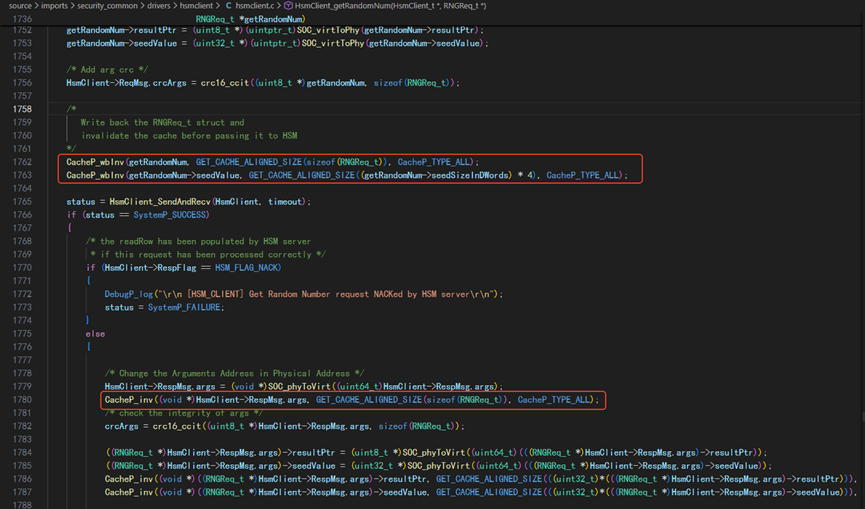
Based on the analysis of the `tifs_am263px_11_00_00_01` example, when the main core and the HSM core request TRNG services, cache coherence management must be performed before data is sent to the HSM core and after data is received back to the main core, as illustrated below. The `GET_CACHE_ALIGNED_SIZE` macro aligns the size of the data to be cache-managed to a multiple of 128 bytes (the cache line size for buffer alignment).
**Question 1:**
Is it necessary to enforce alignment when defining the data, e.g`HsmClient_t client __attribute__((aligned(Mcal_CacheP_CACHELINE_ALIGNMENT)))`? Or is it sufficient to perform alignment solely in `CacheP_wbInv`, `CacheP_wb`, and `CacheP_Inv`? As I understand, TI's flow only does the latter. What impact does omitting the former have?
**Question 2:**
Are the above data alignment (e.g.HsmClient_t client __attribute__((aligned(Mcal_CacheP_CACHELINE_ALIGNMENT)))) and cache coherence management only necessary when the data is used by multiple cores (R5SS0_CORE0, R5SS0_CORE1, R5SS1_CORE0, R5SS1_CORE1, HSM) and the data resides in a cacheable memory region?
If the data is used only within R5SS0_CORE0 or is placed in a non-cacheable region, are the above operations unnecessary?