


Other Parts Discussed in Thread: SYSBIOS
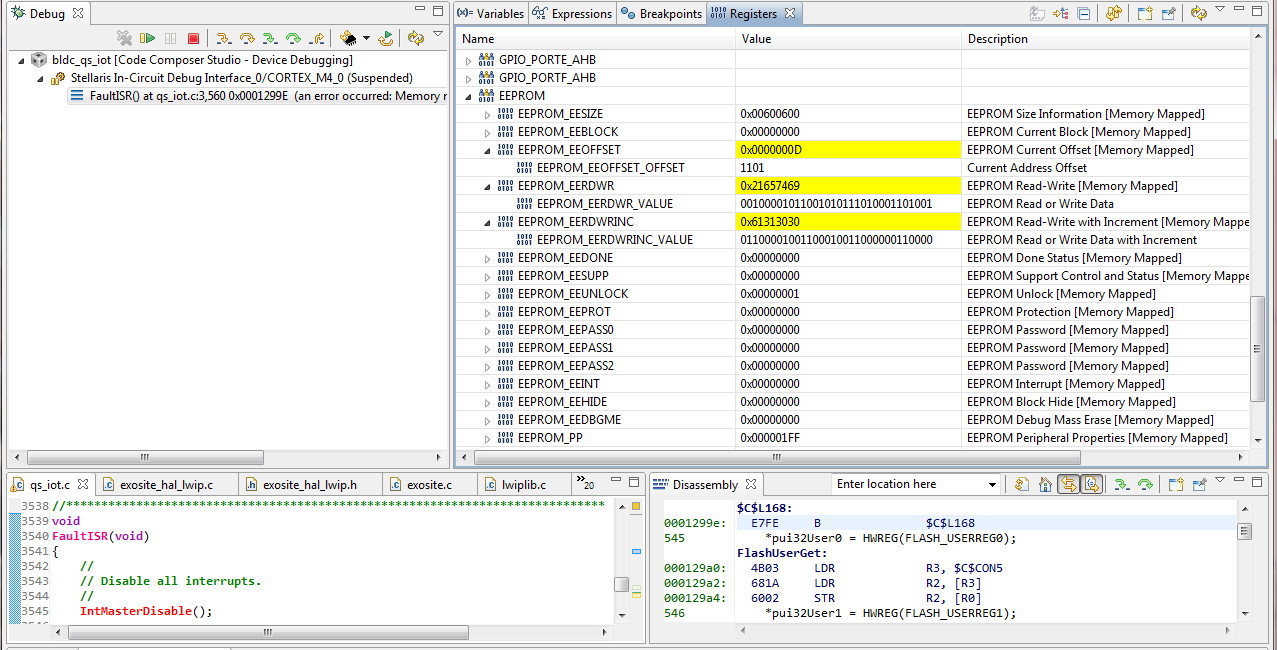
CCS debug shows the address of the Bus Fault to be in SRAM although EEROM read is suspect to be cause of the error. CCS 4dDebug simpulator only highlights the EEROM peripheral registers in yellow, might indicate trouble area?
FAULTSTAT REG 65 BFARV bit 15 is set true indicating a valid Fault address in SRAM & valid exception fault handler interrupt priority took place.
EK-TM4c1294NCPDTI3-XL
At this time not really sure how to back tracking the memory address into the SW inflicting this awful symptom.
Debug information around the error:


The following conditions generate a fault:
■ A bus error on an instruction fetch or vector table load or a data access.
■ An internally detected error such as an undefined instruction or an attempt to change state with
a BX instruction.
■ Attempting to execute an instruction from a memory region marked as Non-Executable (XN).
■ An MPU fault because of a privilege violation or an attempt to access an unmanaged region.
In a fault handler, the true faulting address can be determined by:
1. Read and save the Memory Management Fault Address (MMADDR) or Bus Fault Address (FAULTADDR) value.
2. Read the MMARV bit in MFAULTSTAT, or the BFARV bit in BFAULTSTAT to determine if the
MMADDR or FAULTADDR contents are valid.
Software must follow this sequence because another higher priority exception might change the
MMADDR or FAULTADDR value. For example, if a higher priority handler preempts the current
fault handler, the other fault might change the MMADDR or FAULTADDR value.
2.6.1 Fault Types
Table 2-11 on page 122 shows the types of fault, the handler used for the fault, the corresponding
fault status register, and the register bit that indicates the fault has occurred. See page 182 for more
information about the fault status registers.
Fault | Handler | Fault Status Register | Bit Name
Precise data bus error Bus fault Bus Fault Status (BFAULTSTAT) PRECISE
Register 65: Configurable Fault Status (FAULTSTAT), offset 0xD28
Bit/Field Name Type Reset Description
_________________________________________________________________________
BIT[15] BFARV RW1C 0 Bus Fault Address Register Valid
Value Description
0 The value in the Bus Fault Address (FAULTADDR) register
is not a valid fault address.
1 The FAULTADDR register is holding a valid fault address.
This bit is set after a bus fault, where the address is known. Other faults
can clear this bit, such as a memory management fault occurring later.
If a bus fault occurs and is escalated to a hard fault because of priority,
the hard fault handler must clear this bit. This action prevents problems
if returning to a stacked active bus fault handler whose FAULTADDR
register value has been overwritten.
This bit is cleared by writing a 1 to it.
___________________________________________________________________________
Bit[9] PRECISE RW1C 0 Precise Data Bus Error
Value Description
0 A precise data bus error has not occurred.
A data bus error has occurred, and the PC value stacked for
the exception return points to the instruction that caused the fault.
1 When this bit is set, the fault address is written to the FAULTADDR register.
This bit is cleared by writing a 1 to it.


