


This post a continuation from other posts all gaining evidence in the mystery - who done it and why remains opaque.
Almost seems as if a trace on EK-TM4C1294i3-XL PCB could be crossed with some other trace or internal NVIC line/register.
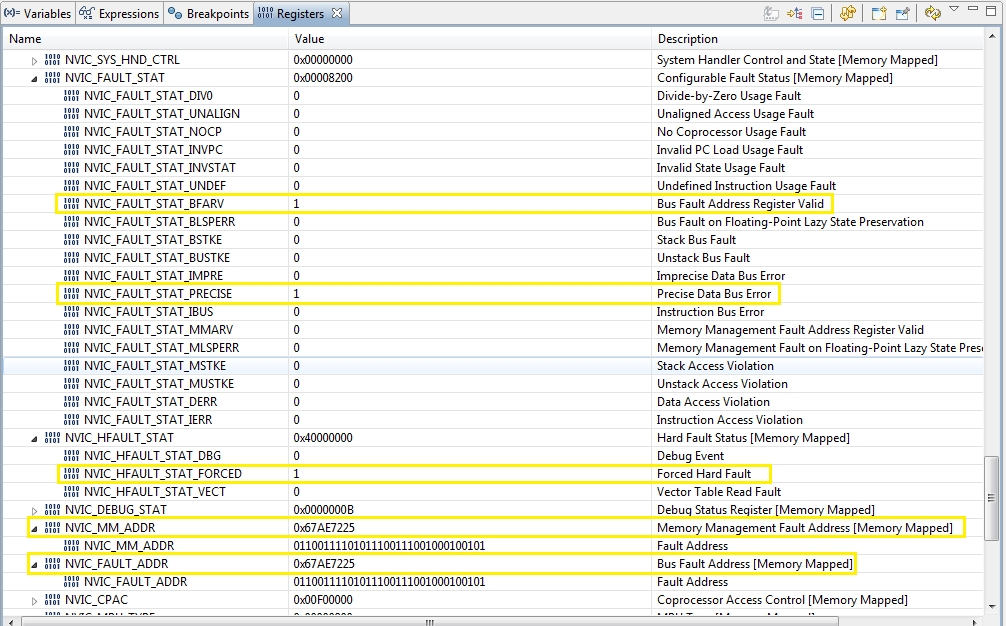
Seemingly out of place the EPI0 peripheral is not configured yet the External power control for EPI0 in CCS debug is showing set 1 enabled. That EPI0 happens to fall on the NVIC fault address more than one time (0x67AE7225).
Control register 7 has RESC=0x8 or WDT0 interrupt was cause of the MPU reset.
Previous posts to issue:
https://e2e.ti.com/support/microcontrollers/tiva_arm/f/908/p/425490/1520868#1520868
https://e2e.ti.com/support/microcontrollers/tiva_arm/f/908/p/425490/1519603#1519603
Bus Fault:




{kind=link}