


Source: (emac.c)
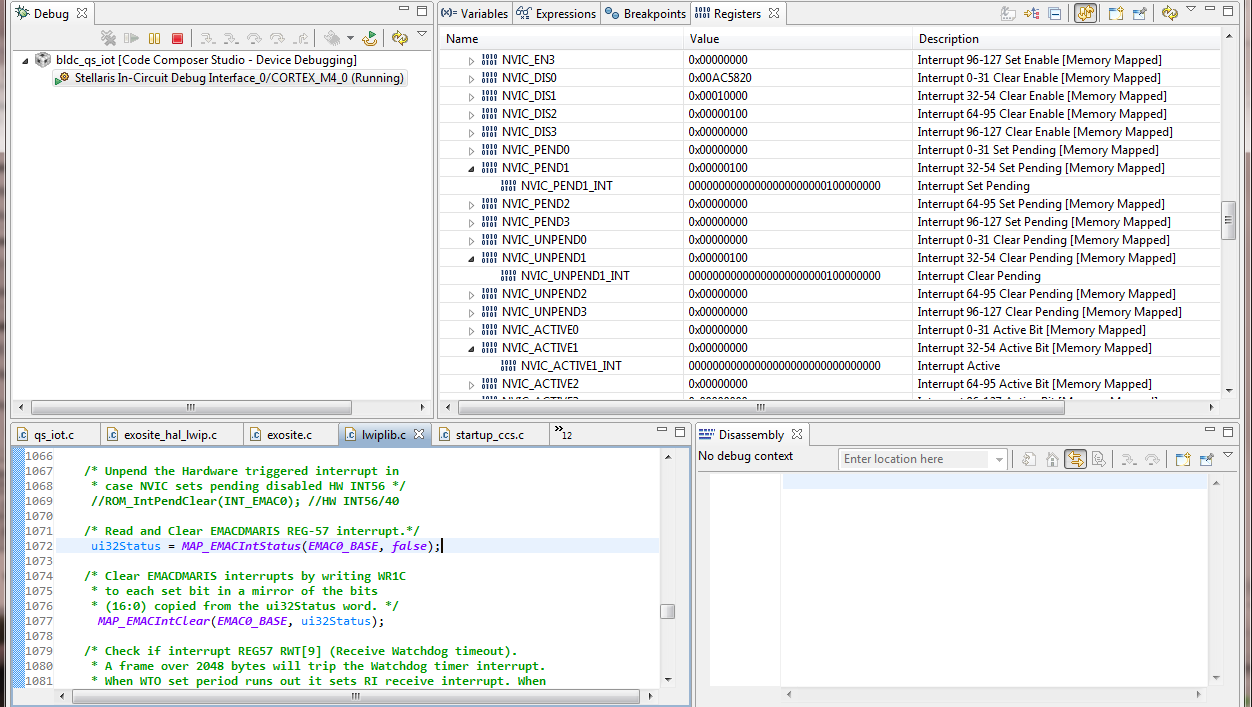
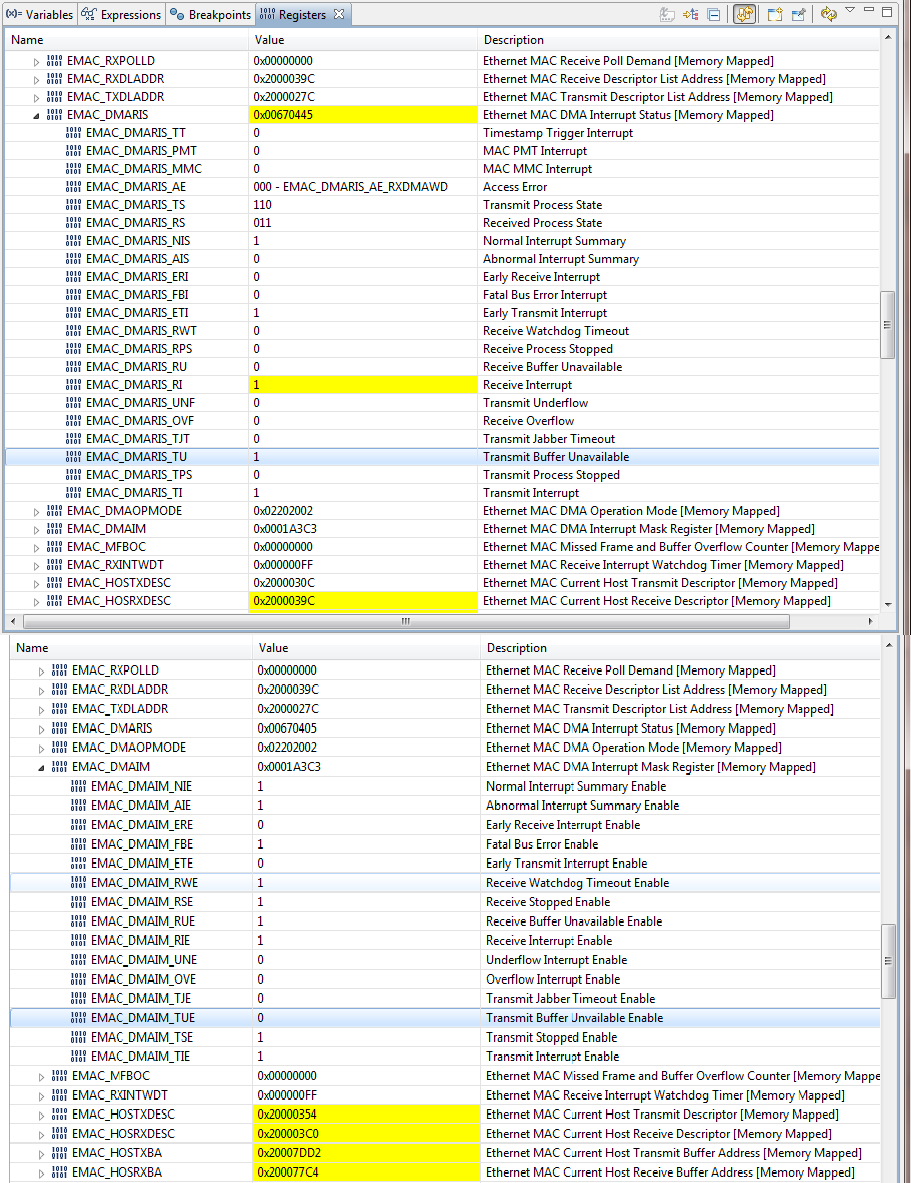
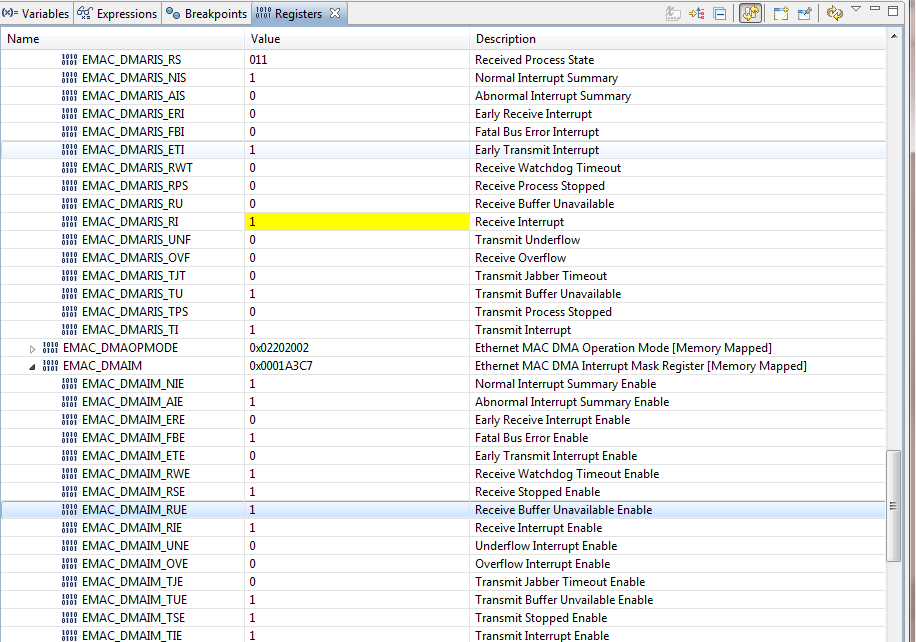
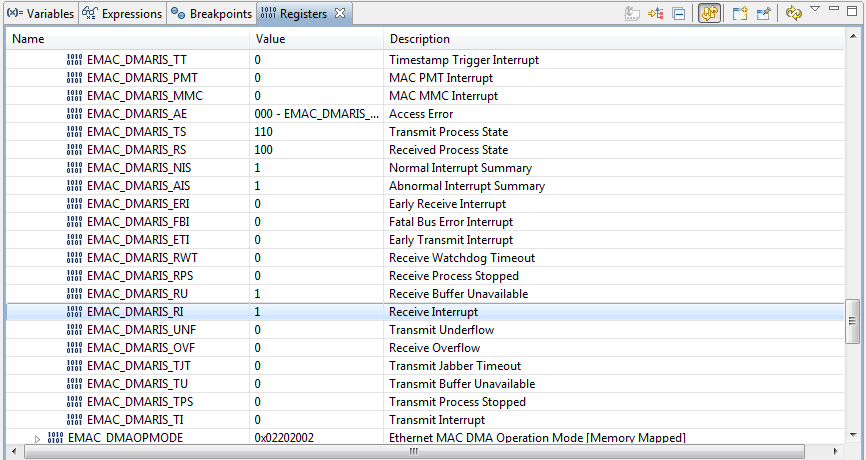
EMACIntStatus() returns the interrupt unmask values of the EMACMARIS REG57 if Boolean (false) and masked values EMACDMAIM REG59 if (true).
The masked returned value (true) claims the EMACDMAIM REG59 0xC1C to be unmaskable and manually OR'd with EMAC_NON_MASK_INTS.
Yet the lower 16:0 bits are maskable in the EK-1294 EMACDMAIM and only the upper 16 bits EMACDMARIS TS/RS status bits are being manually masked. So it looks like the lower 16 maskable interrupts bits are being ignored during the OR process.
Seems better to OR the EMAC_MASKABLE_INTS values with EMACDMAIM against interrupt status register EMACDMARIS and perhaps manually mask (OR) the TS/RS bits?
EMACIntStatus(uint32_t ui32Base, bool bMasked) { ~~~~~~~~~~~~~~~~~
if(bMasked)
{
ui32Val &= (EMAC_MASKABLE_INTS | HWREG(ui32Base + EMAC_O_DMAIM));//EMAC_NON_MASKED_INTS
}


{kind=link}