Other Parts Discussed in Thread: EK-TM4C123GXL
Gents,
I have no experience to deal with this one, and it seems that my resources are gone... maybe some of you can suggest an approach:
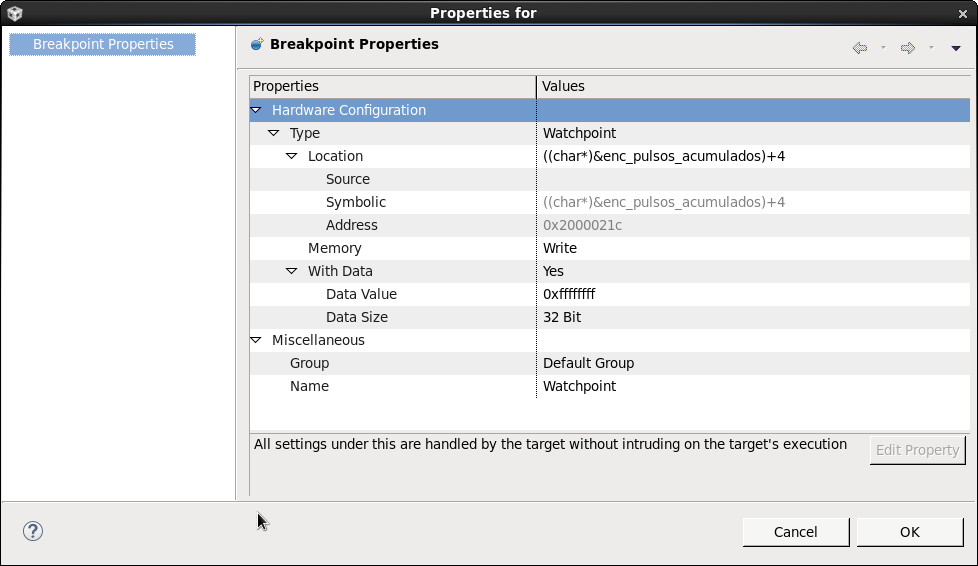
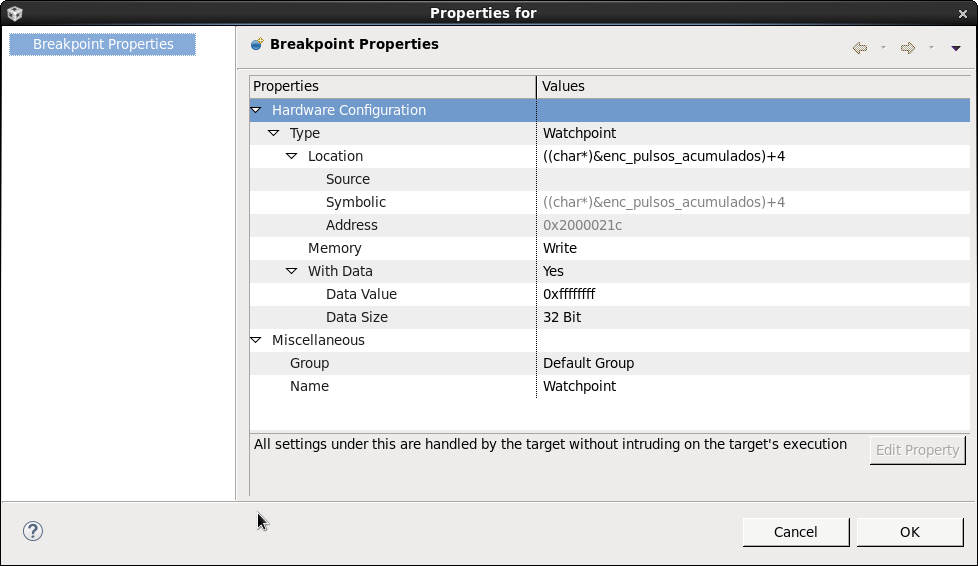
On a TM4C123 project using CCS, there a variable that appears to be "corrupted" somewhere else. Details:
- It is a public variable declared on the main_project.c: int64_t enc_pulsos_acumulados;
- It's value is only changed in one and only one location. It is behaving as expected, accumulating "small values" such as 805, 806... Suddenly, the high bits of this int64 all become FF FF FF FF...
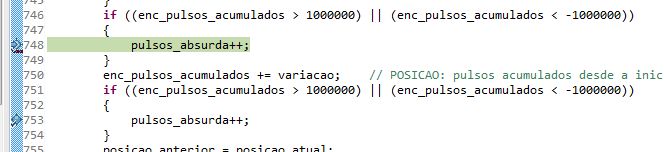
- I added a couple of tests before and after the only location where it is changed, and it shows that actually this corruption comes "somewhere else". Piece of code posted below (pasted as an image just to better illustrate where the breakpoint stoped.
I also looked at the memory location to check if eventually there was an array or something nearby, but it does not seem to be the case (image below).
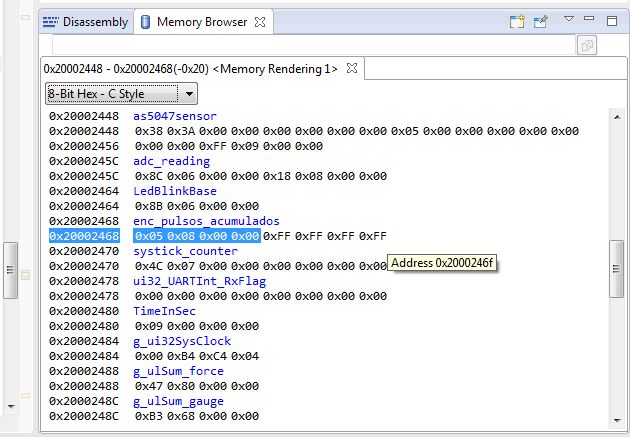
I tripled checked and there is no other attribution to this variable elsewhere.
Any suggestions as how to debug and find what's happening?
Thanks!!!