Fellows,
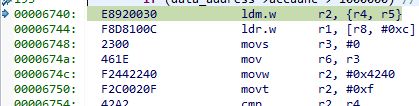
This is a screenshot of CCS 6.1 trying to debug TM4C123x. This project suddently began to give me all sorts of headaches...
The displayed variable is called as5047sensor. It is stored in location 0x20004835, as can be seen both on the yellow pop-up window and on the while expressions window.
The element accuunc was recently set to 0, and such attribution in fact worked. The value on the right (white) part of the image is correctly 0, in address 0x20004849. However, on the same moment, the yellow popup shows a huge number (all formats properly visible there):
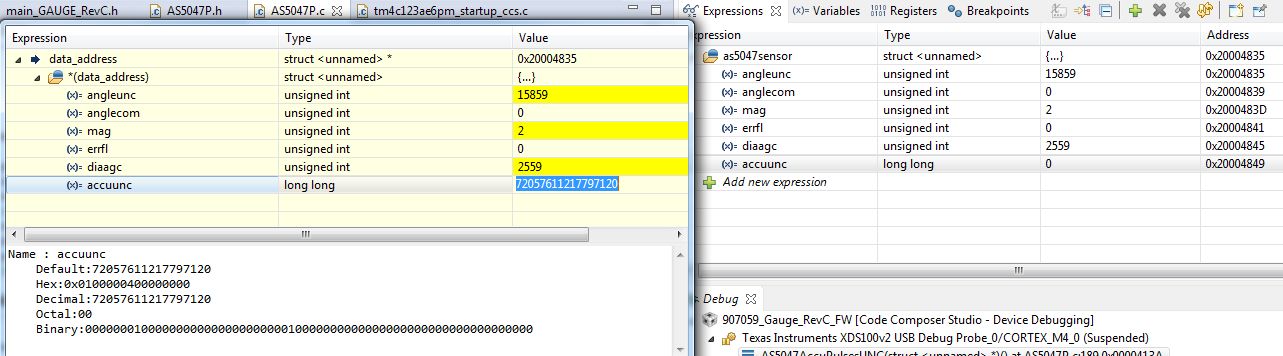
There is something quite weird with that variable, as the next line would try to access as5047sensor.accuunc, but that causes a FaultISR.
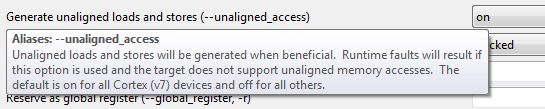
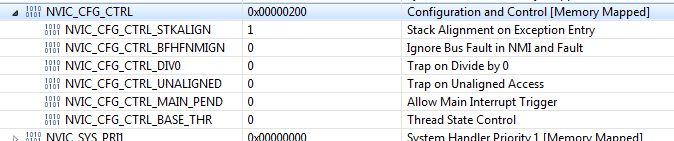
Patiently tried to debug the FaultISR as per available documents, but found no evident cause. I know not enough assembly to figure this out, but there was nothing popping out as too illegal. Checking the NVIC fault registers, one hint is a bit set on Unaligned Access Usage Fault.
Further info: general interrupt is disable at this stage.
Any suggestions are most welcome!!!