Part Number: EK-TM4C123GXL
connecting a scope to a GPIO output pin I can measure the time its takes
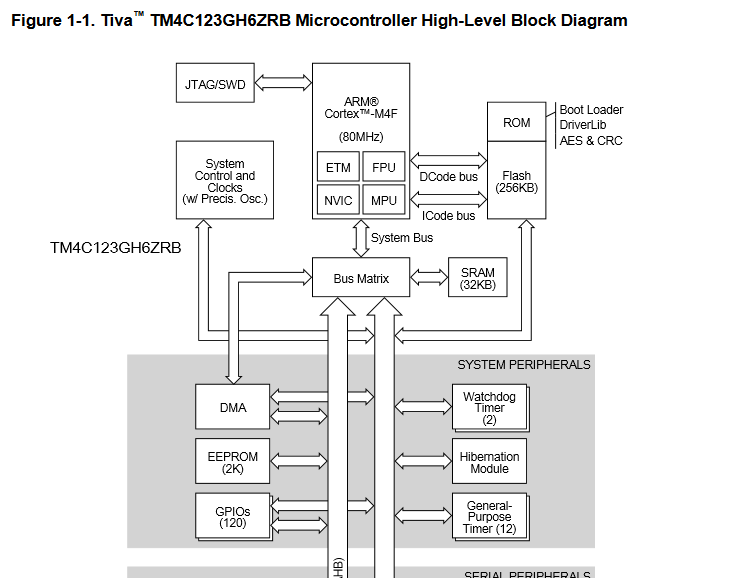
for a loop to repeat. The loop simply toggles the GPIO pin. The clock rate
on the Tiva C series launchpad is documented as 80 MHz (12.5 ns cycle).
Running the code from ROM I measured a pulse width of 100ns (8
cycles). From RAM I get 125ns instead (10 cycles).
Why running from RAM is slower in this case? I was actually expecting the
opposite, a faster RAM execution.
Thanks,
Rodrigo
from ROM execution
00000000000002b0 0000001c <loop()>:
2b0: ldr r3, [pc, #20] ; (2c8 <loop()+0x18>)
2b2: ldr r2, [r3, #4]
2b4: ldrb r1, [r3, #21]
2b6: movs r3, #0
2b8: str.w r3, [r2, r1, lsl #2]
2bc: ldr.w r3, [r2, r1, lsl #2]
2c0: mvns r3, r3
2c2: str.w r3, [r2, r1, lsl #2]
2c6: b.n 2bc <loop()+0xc>
2c8: .word 0x2000026c
from RAM execution
200002b0: ldr r3, [pc, #20] ; (200002c8 <loop()+0x18>)
200002b2: ldr r2, [r3, #4]
200002b4: ldrb r1, [r3, #21]
200002b6: movs r3, #0
200002b8: str.w r3, [r2, r1, lsl #2]
200002bc: ldr.w r3, [r2, r1, lsl #2]
200002c0: mvns r3, r3
200002c2: str.w r3, [r2, r1, lsl #2]
200002c6: b.n 200002bc <loop()+0xc>
200002c8: .word 0x20000a6c