Other Parts Discussed in Thread: EK-TM4C1294XL
Hi everyone,
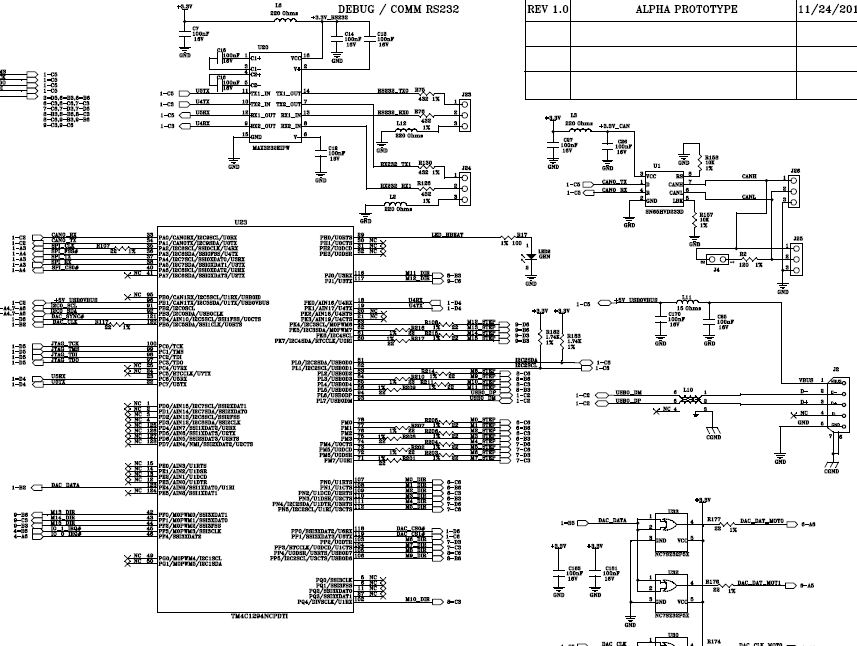
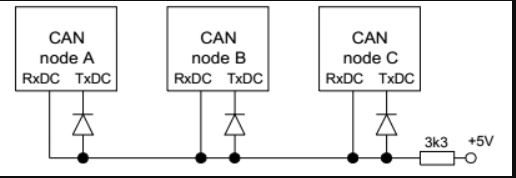
I have two nearly identical boards, using nearly the same core. They communicate via CAN Bus.
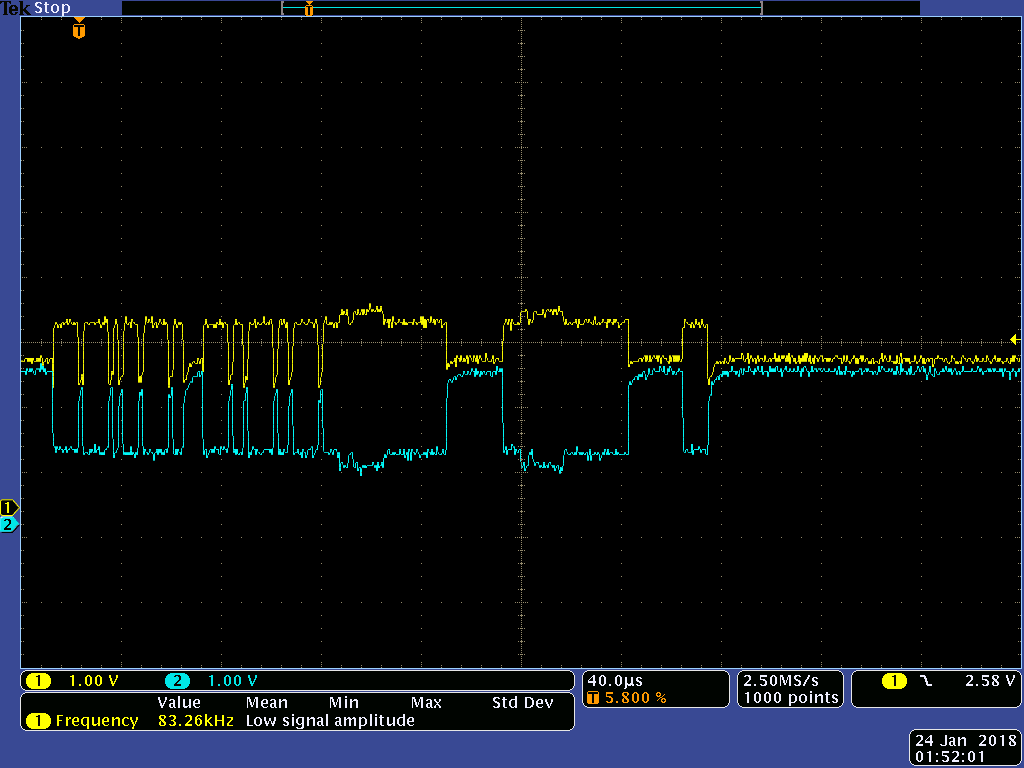
I have CAN Bus error occuring in only one of them. I made sure it is not a single board problem: it does repeat in the whole batch of 5.
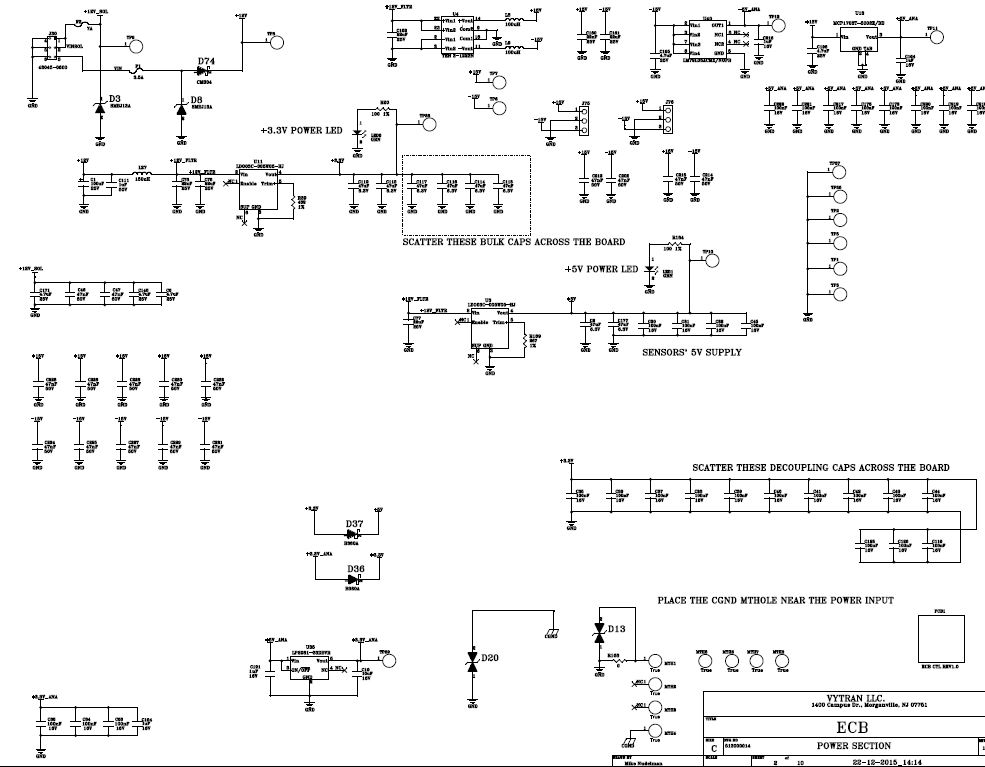
Both boards us Artesyn DC-DC POL 12V / 3.3V converter for VDD, 3A capable unit..
The one that seems to work without problems has a separately derived VDDA, made from the external 12V power supply run via an isolated POL, and then a 5V LDO, and then a 3.3V LDO. (I do have a diode between VDD and VDDA in case the chip wants to lock up).
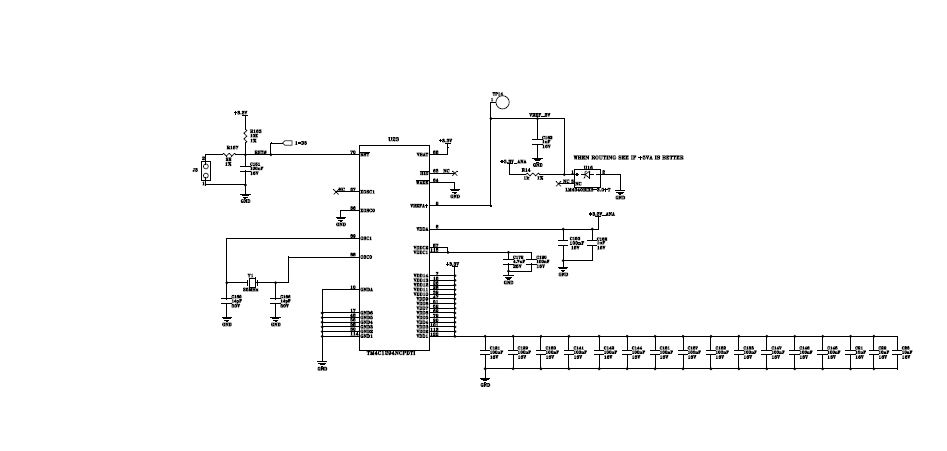
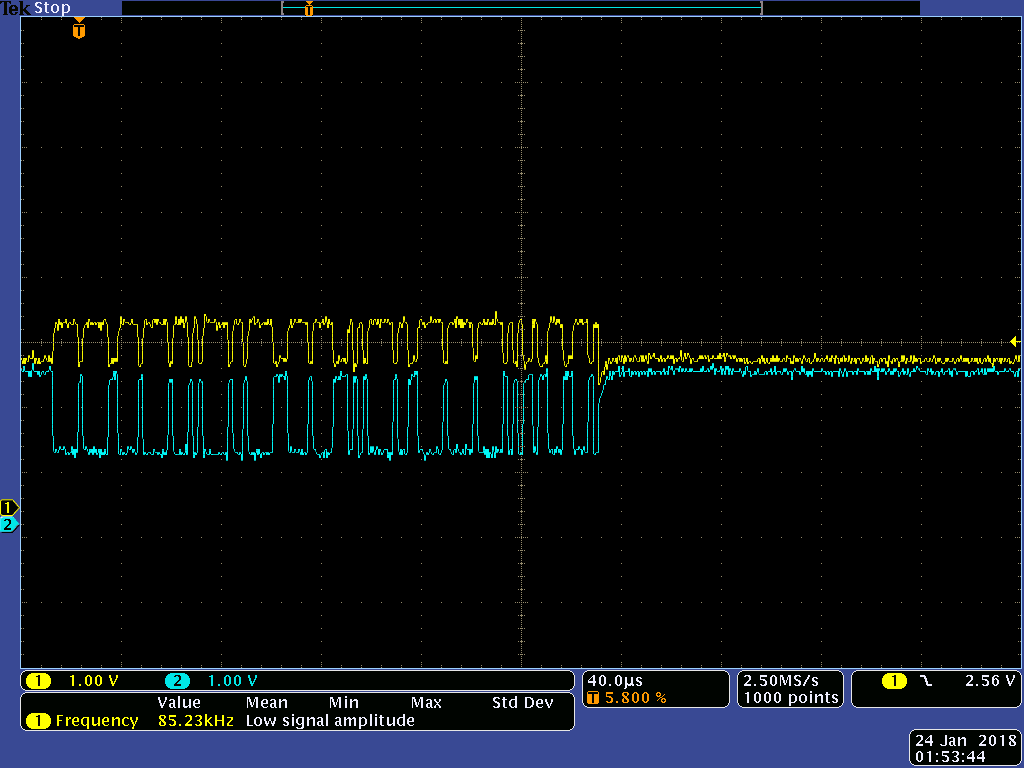
The one that has problems has the same 3.3V bus going to both VDD and VDDA, which is nothing unusual.
I decided to short the two voltages in the board that works (where the voltages are derived independently) and it started exhibiting exact same problem.
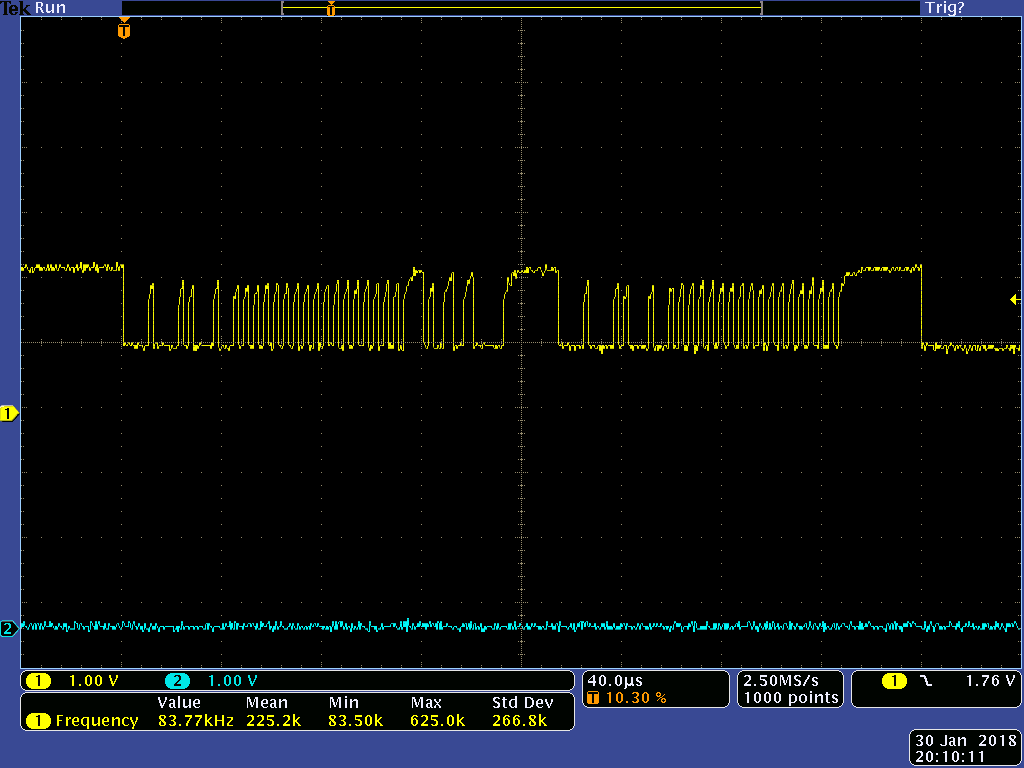
The rest of the board seems to work, the code runs fine until the CAN communication occurs at which point it signals an error.
This problem only occurs after a power-cycling: initially, when the board is programmed via the debugger without power cycling, it works fine.
In the Application Report SPMA056–October 2013, the "System Design Guidelines for the TM4C129x Family of Tiva™ C Series Microcontrollers ", I have this which I am not sure I fully understood:
3.4.1 Microcontroller Power Supply.
"The supply connected to VDD must accommodate a short period (40μSec to 60μSec) of additional inrush
current that occurs as the decoupling capacitors connected to the LDO on the VDDC rail charge up to the
VDDC voltage level. Internal circuitry limits the inrush to the IINRUSH(max) specified in the data sheet for the
part. The supply connected to VDD can self limit the current it supplies to something less than the
maximum IINRUSH, however that extends the period it takes to bring VDDC up to operating voltage."
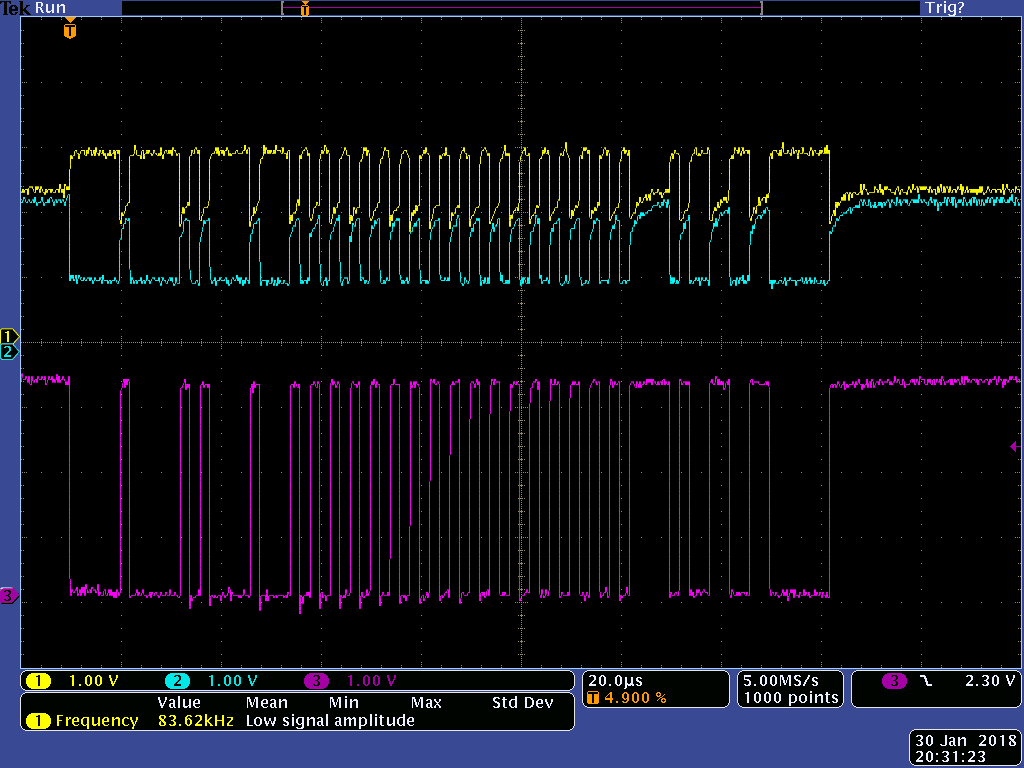
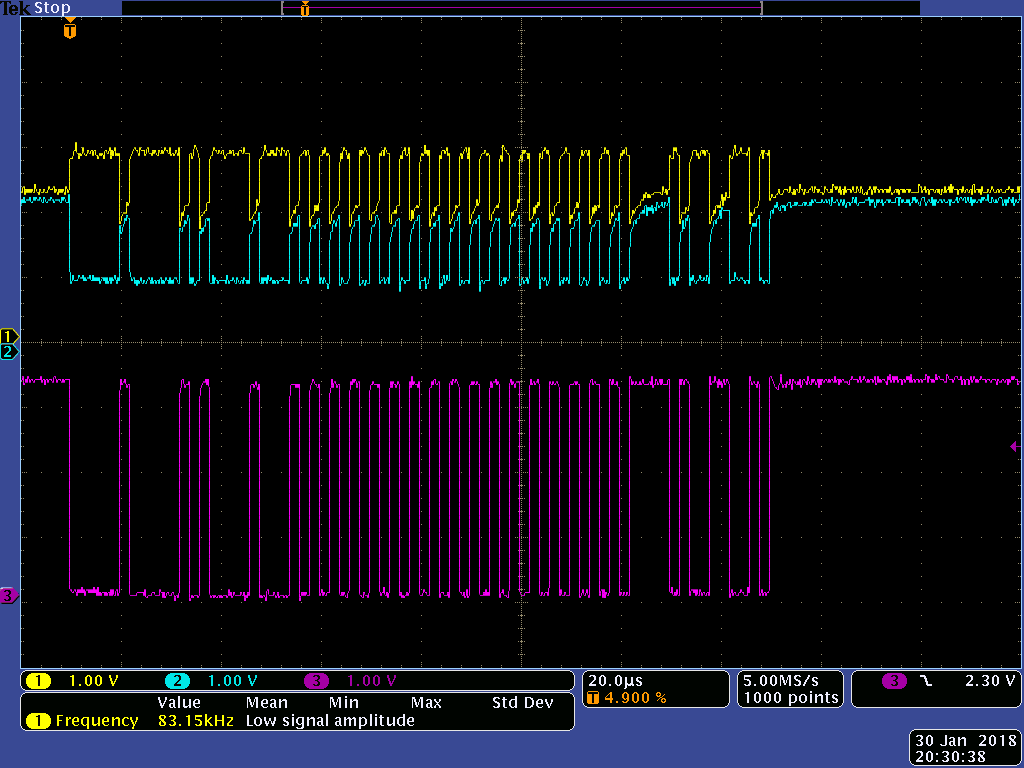
This is the setup of the board with the same VDD/AVDD.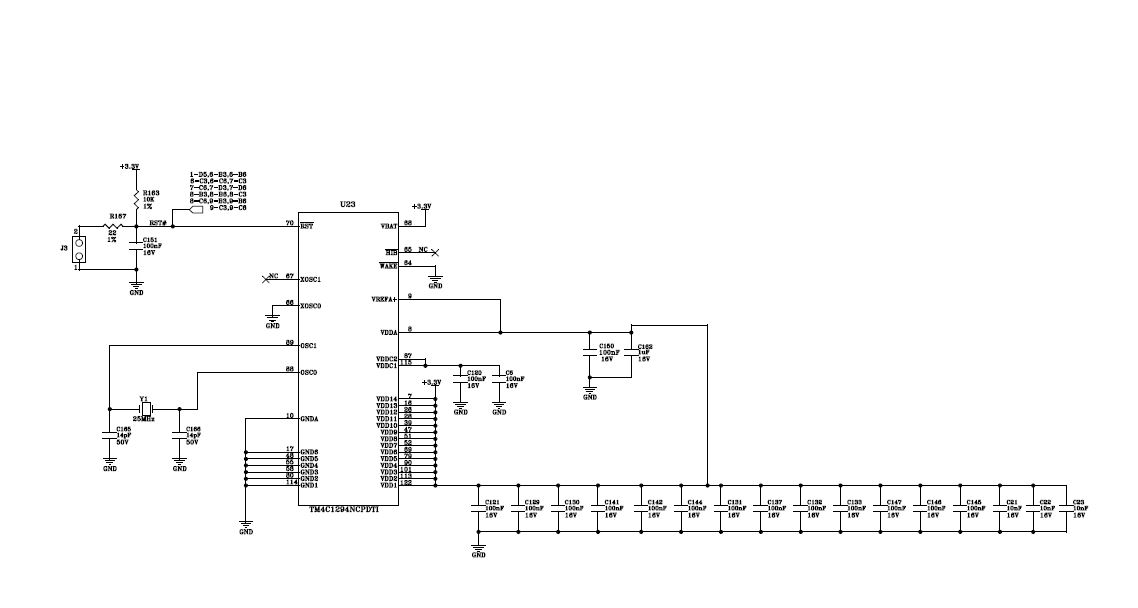
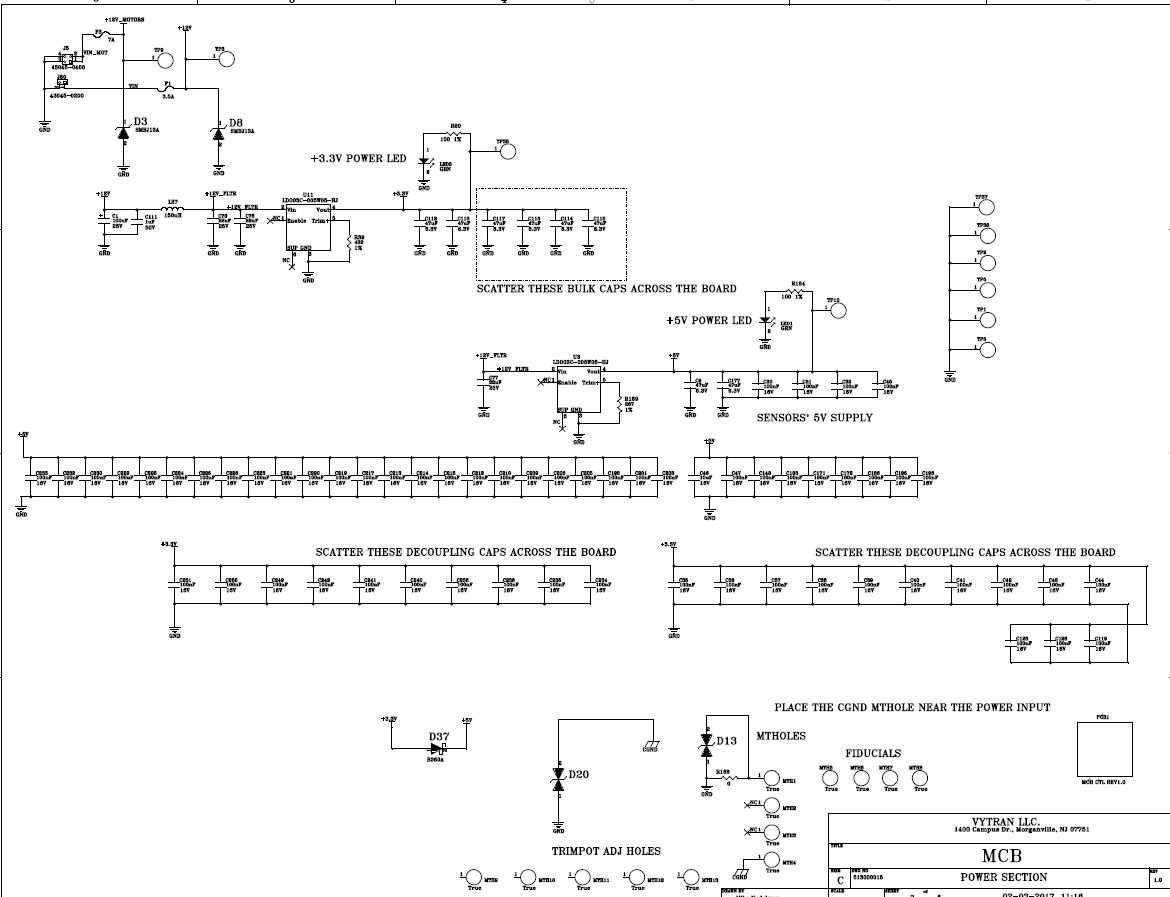
This is the setup with separate VDD/AVDD