


Tool/software: Code Composer Studio
I am working on a large project completely written in C (other than the standard startup code). After some recent code changes, it started crashing (ending up in FaultISR). It happens consistently after running for about six seconds. I have been following the troubleshooting instructions in http://www.ti.com/lit/an/spma043/spma043.pdf, which I'll get to below, but first a summary:
- The program runs on "bare metal" (no RTOS).
- There is plenty of stack space.
- I don't think it is a problem with failing to enable a peripheral before using it (although I have done that before).
The source of the problem is elusive:
- If print additional debug messages, can get the problem to disappear. But I want to know the root cause and fix it, not just make it go away.
- Using the stack pointer to find the PC that got pushed when FaultISR was called leads to code that hasn't been changed recently. Can delete that code and the problem moves somewhere else.
- Using LR to find what was going on one more step back leads to code that couldn't possibly call the code the PC leads to (although it could happen the other way around).
- The changed code seems unrelated to the crash, other than perhaps moving things around in memory or affecting the timing.
- It crashes in the same way on a second set of hardware (both of which have been well used without problems in the past).
I have not done debugging with this (or any ARM based) MCU at this level before, so the answer might be under my nose and I am just missing it. Anyway, this is the result of one recent debug session that I think follows the process from http://www.ti.com/lit/an/spma043/spma043.pdf with some additional steps to keep the stack as clean as possible before the crash.
Using CCS V9 IDE and the TI v18.12.2.LTS compiler. More on optimization levels later.
Disabled the debug configuration option to auto run to main() on program load or restart. Manually set a breakpoint on main(). Filled the 2048 byte stack at address 0x20005EB8 with 0xAA.
Re-loaded the program using the debugger. It is stopped on _c_int00_noargs() in boot_cortex_m.c. The stack is unchanged (all 0xAA).
Let it run to the beginning of main(). It used 10 32-bit words of stack space getting here. The stack pointer is now pointing to __STACK_END, so re-filling the stack with 0xAA again, so can see what it does after this.
Letting the program continue to run from the beginning of main(). After about 6 seconds it stopped at a breakpoint I had set at the beginning of FaultISR(). It does this consistently.
- The bottom of the stack still has 332 bytes filled with 0xAA, so it didn't run out of stack space.
- I also ran it with twice the stack space, with exactly the same result.
- It seems a bit odd to me that some portions of the stack (other than the bottom) still have 0xAA in them. Perhaps there are some arrays or uninitialized structures used as automatic variables which get space allocated for them but don't get initialized.

- Core registers are:



- Some NVIC registers:
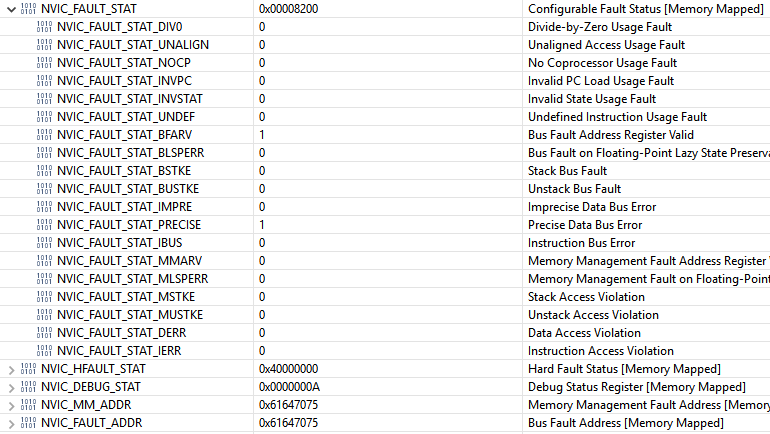
- NVIC_FAULT_STAT is 0x00008200, with these bits set:
- NVIC_FAULT_STAT_BFARV - Bus fault address register valid
- NVIC_FAULT_STAT_PRECISE - Precise data bus error

- Since NVIC_FAULT_STAT_BFARV is set, can read NVIC_FAULT_ADDR, which is 0x61647075. That isn't a valid memory address. So the bus fault was precise, probably a read from address 0x61647075.
- I have more than just a while(1) in FaultISR(), but at this breakpoint SP has not yet been adjusted for them. So the standard ISR stack frame should exist at the SP value of 0x20006620. So the register values there are:
R0: 0x61647075 (the fault address)
R1: 0x0000161D
R2: 0x00000001
R3: 0x000000B3
R12: 0x00029C2B
LR: 0x00013CFD
PC: 0x00003CF8
xPSR: 41000000- Shouldn't PC be an odd number (like LR) to indicate that the TM4C123 is using the Thumb instruction set?
- Plugging the PC into the disassembly window:
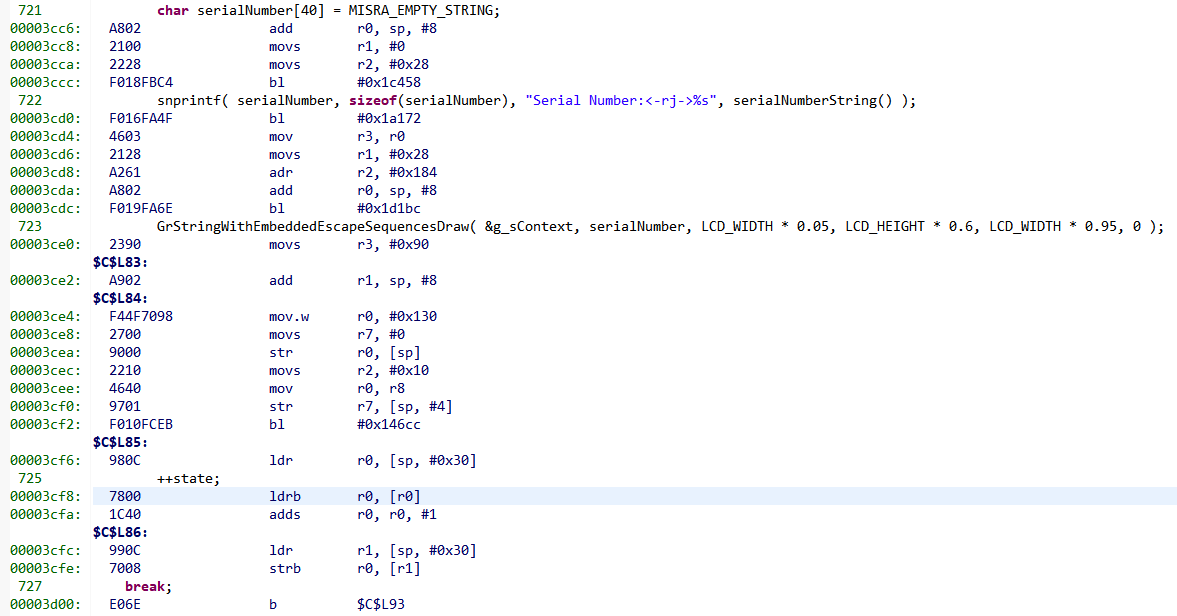
- So doing "ldrb r0, [r0]" when r0 has the value 0x61647075 causes a bus fault. That isn't surprising.
- Double-clicking on that line to set a breakpoint on it, then double-clicking on the breakpoint to open that line in the C source ("++state;"). It is part of function lcdDisplayUpdate() which uses a state machine implemented as a switch statement.
case DISPLAY_LIFTER_SERIAL_NUMBER: { GrContextFontSet(&g_sContext, FONT_SANS_SERIF_23px); char serialNumber[40] = MISRA_EMPTY_STRING; snprintf( serialNumber, sizeof(serialNumber), "Serial Number:<-rj->%s", serialNumberString() ); GrStringWithEmbeddedEscapeSequencesDraw( &g_sContext, serialNumber, LCD_WIDTH * 0.05, LCD_HEIGHT * 0.6, LCD_WIDTH * 0.95, 0 ); ++state; } break; - State is declared at the top of the function like this:
static state_t state = INITIAL_STATE;

- It isn't apparent to me how the address of the variable "state" would get messed up such that trying to read its value with "ldrb r0, [r0]" would access address 0x61647075 rather than something in SRAM (0x2000xxxx). I don't know the Thumb instruction set at all, so maybe there is a clue in the disassembled code that I am not seeing.
- Taking a look further back at the disassembled code around the value of LR on the stack, 0x13CFD, expecting the previous instruction to be a branch to the function in which it crashed. Need to ignore the set LSB, which just indicates it is using the Thumb instruction set, so looking at 0x13CFC.

- Actually, the important instruction is the one before, in this case "bl #0x13b04".
- That is in function tracepointLog(), which is used to record debug info for later printing.

- Looking at the code at 0x13b04.
- That is the beginning of function incrementTracepointLogIndex(), which is a helper function for tracepointLog(). It makes sense that it would be called from tracepointLog().
- Based on this being the target of the branch in LR, I would think that it would be the function in which the crash occurred. Maybe it is.
- But based on the PC on the stack when we reached FaultISR(), the crash occurred in lcdDisplayUpdate(). I don't know what to make of that.
- incrementTracepointLogIndex() is a simple function. I don't see how it would cause a crash.
I am not sure how to dig any deeper into this specific crash. I am trying some other things hoping to get more info, but any hints about how to debug this would be greatly appreciated.
Steve

