Part Number: TM4C129XNCZAD
After heavy testing, I'm seeing a few times where my code ends up in the FaultISR with an precise data bus error. In the past, I've found the "Diagnosing Software Faults in Stellaris Microcontrollers" document (AN01286) to be quite helpful. However, after trying everything in this document I'm still stumped on this one.
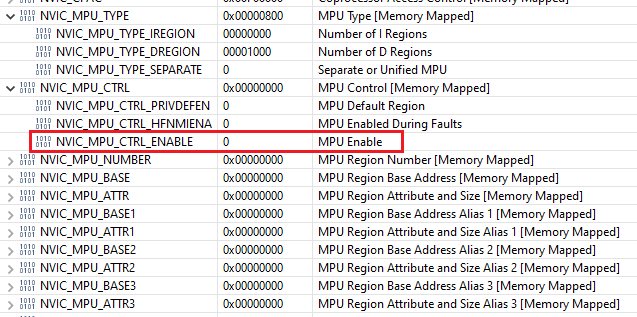
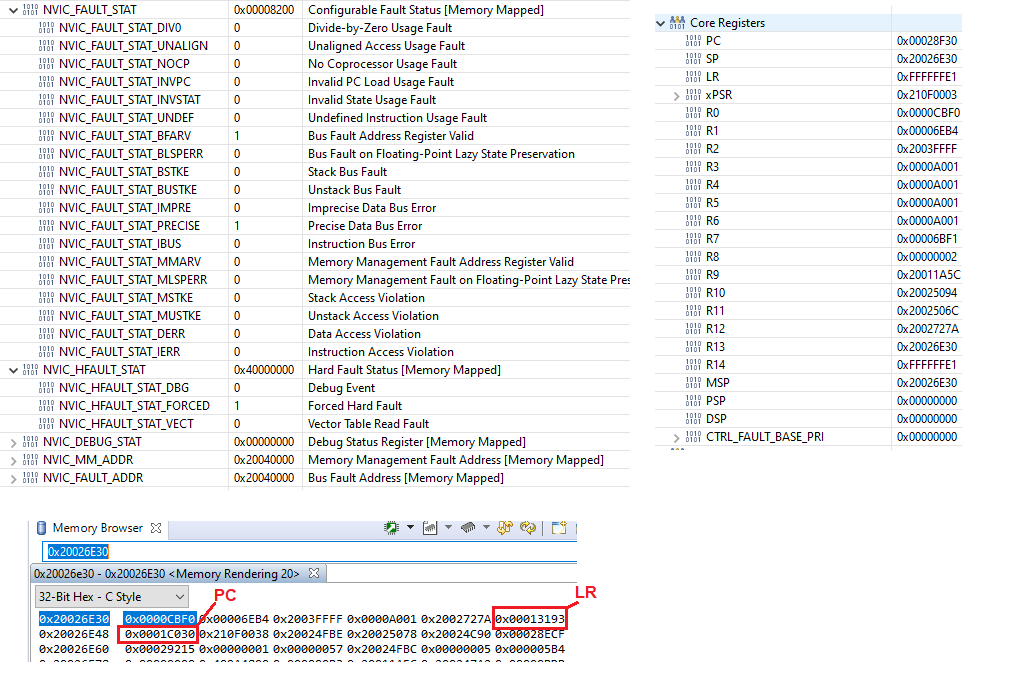
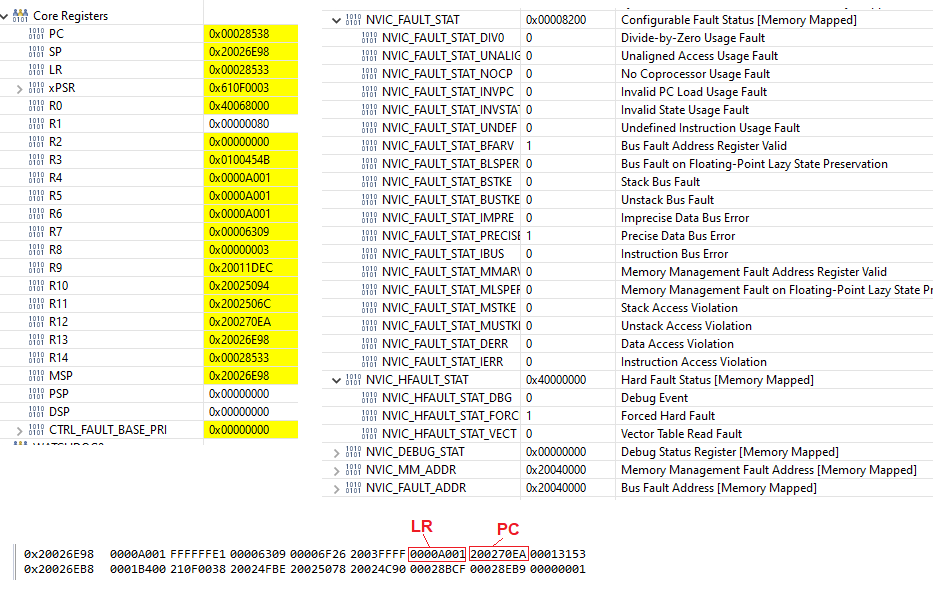
When in the FaultISR function, the core registers, fault registers and memory of the stack are shown below.
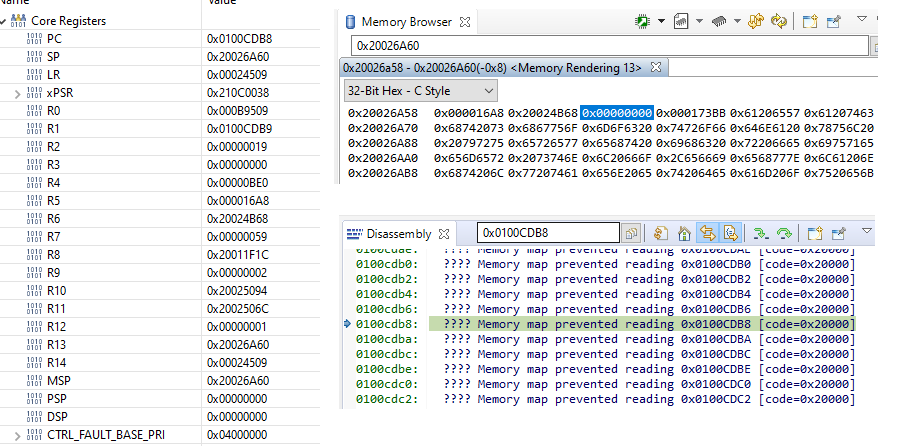
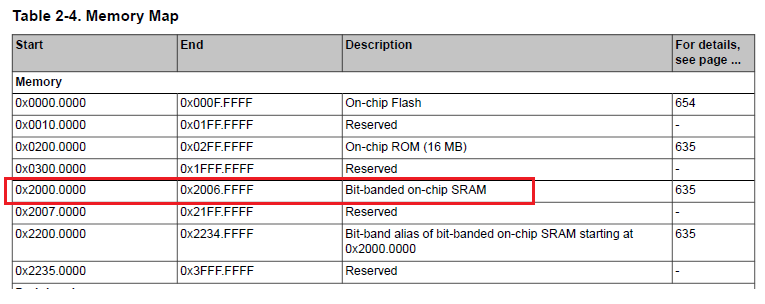
The program counter is not an actual section of code. As the memory map from the TM4C129XNCAD datasheet shows below, this would be in SRAM. Also, the fault address (0x20040000) is in SRAM too. However, note that despite the memory map saying SRAM goes from 0x2000000 to 0x2006FFFF, I believe the valid area would only be from 0x20000000 to 0x2003FFFF since the TM4C129XNCAD datasheet states the microcontroller has 256K of internal memory (section 8, pg 633 of the datasheet) and my tm4c129xnczad.cmd file has SRAM length specified as 0x00040000.
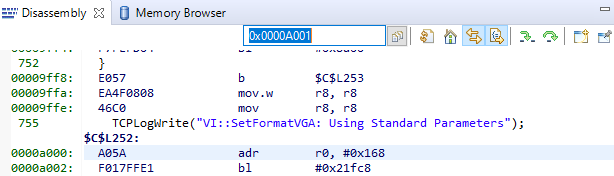
The link register on the stack (0x0000A001), does point to actual code (shown in the image below). However, as far as I can tell, the code in the TCPLogWrite function is harmless.
Questions:
- Is the bus fault of 0x20040000 indicating that I've overrun the data area? For example, something I might get if I were indexing through an array and went wildly past the last index to the point of being outside of the SRAM area (i.e. hitting memory address 0x20040000)?
- Is it safe to say the issue is likely happening in the TCPLogWrite function or might the LR be a red herring?
Thanks in advance for any thoughts anyone might have.