Part Number: TM4C129XNCZAD
Other Parts Discussed in Thread: EK-TM4C1294XL, EK-TM4C129EXL, MSP-EXP432E401Y, MSP432E401Y
Hi,
We have been struggling with a very strange hard fault which either occurs every time after a while in the same conditions or never occurs (compile output dependent).
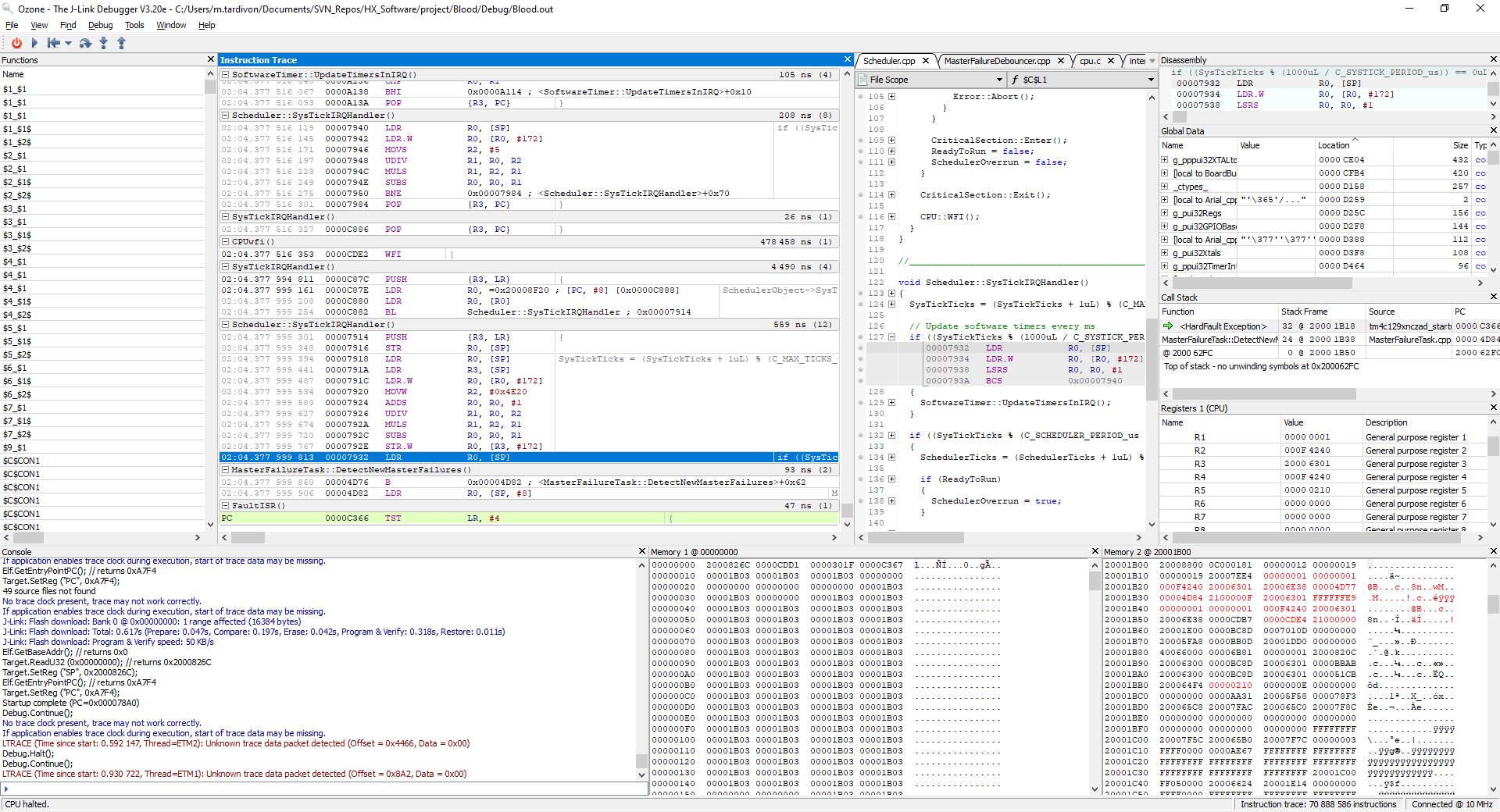
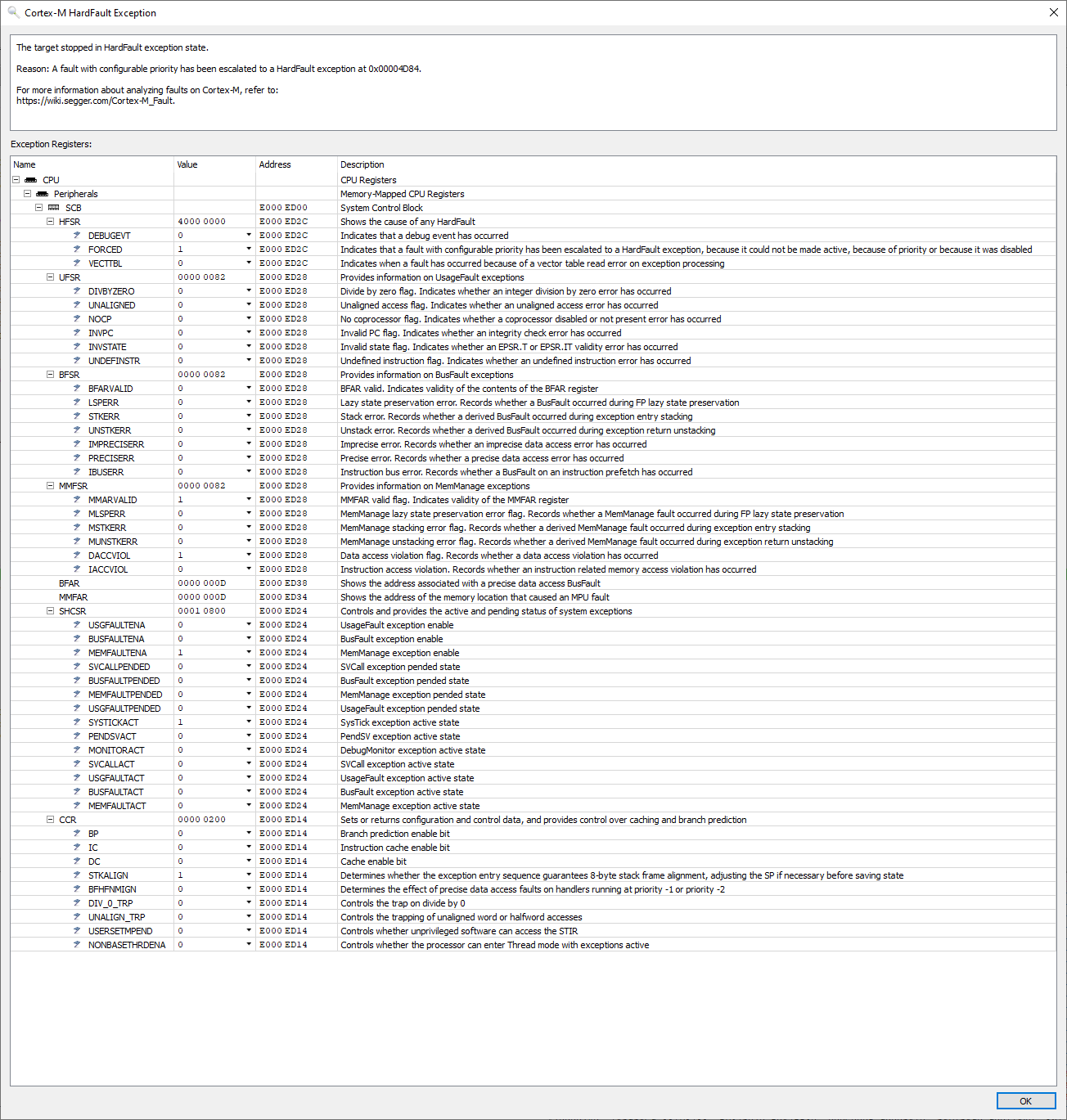
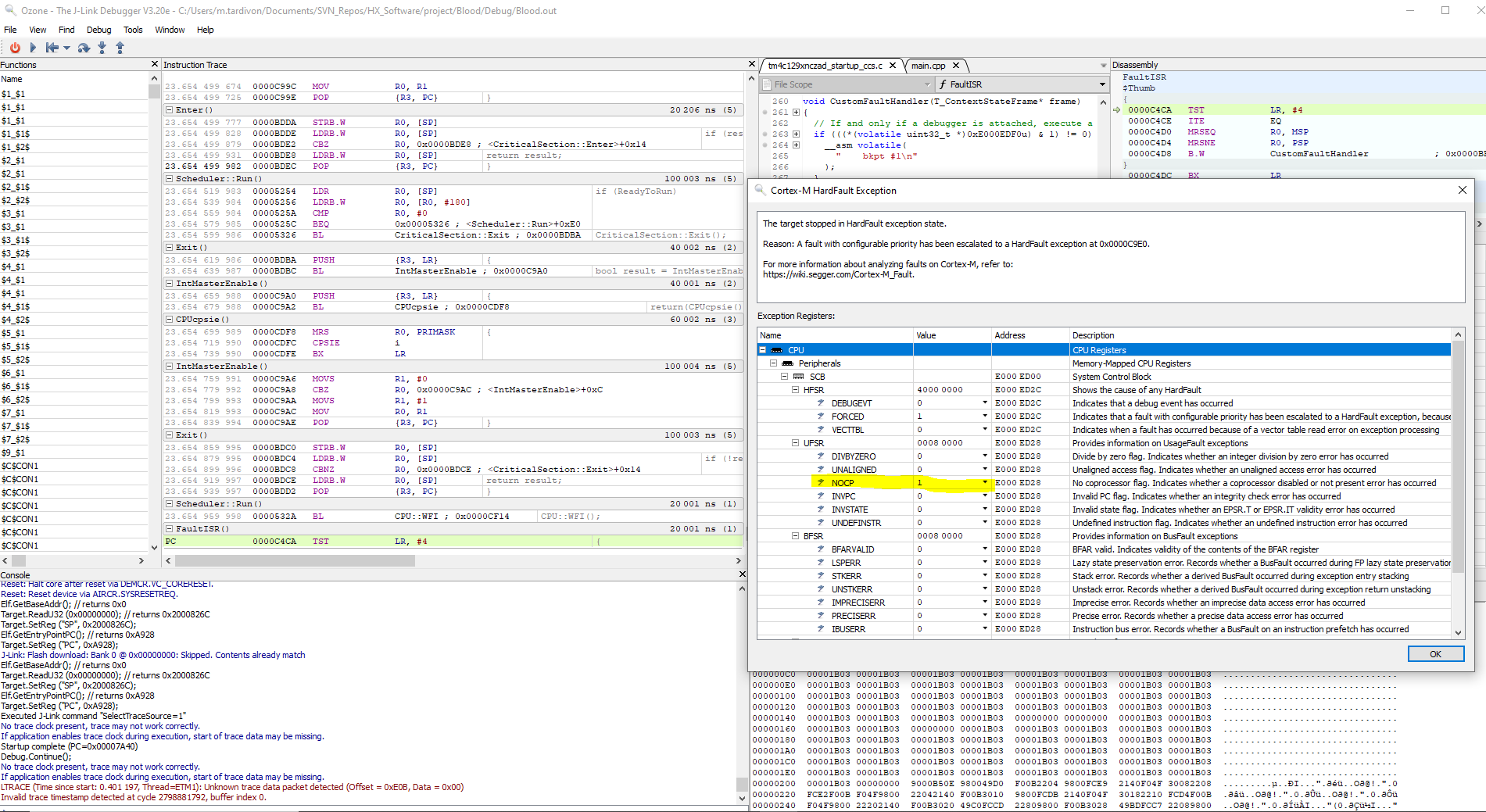
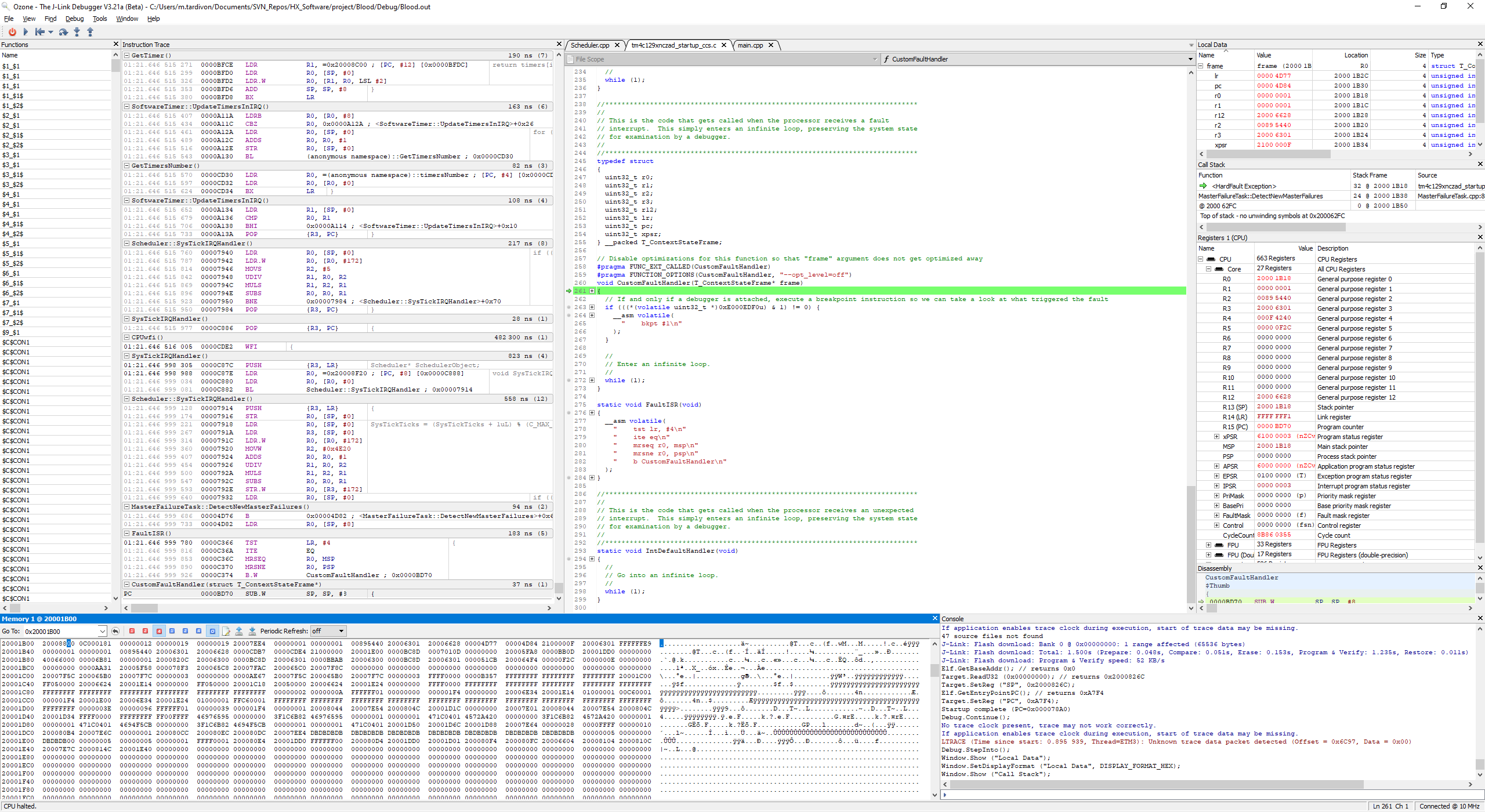
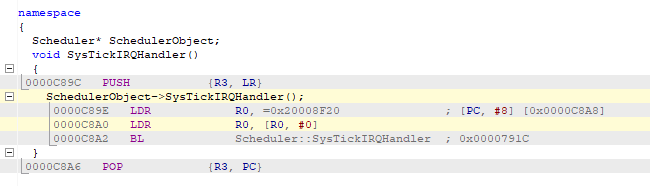
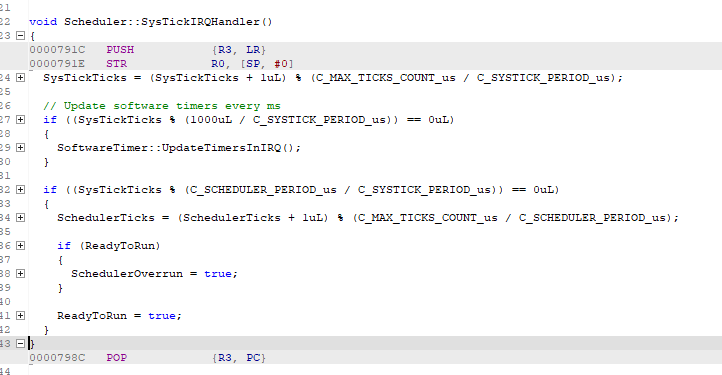
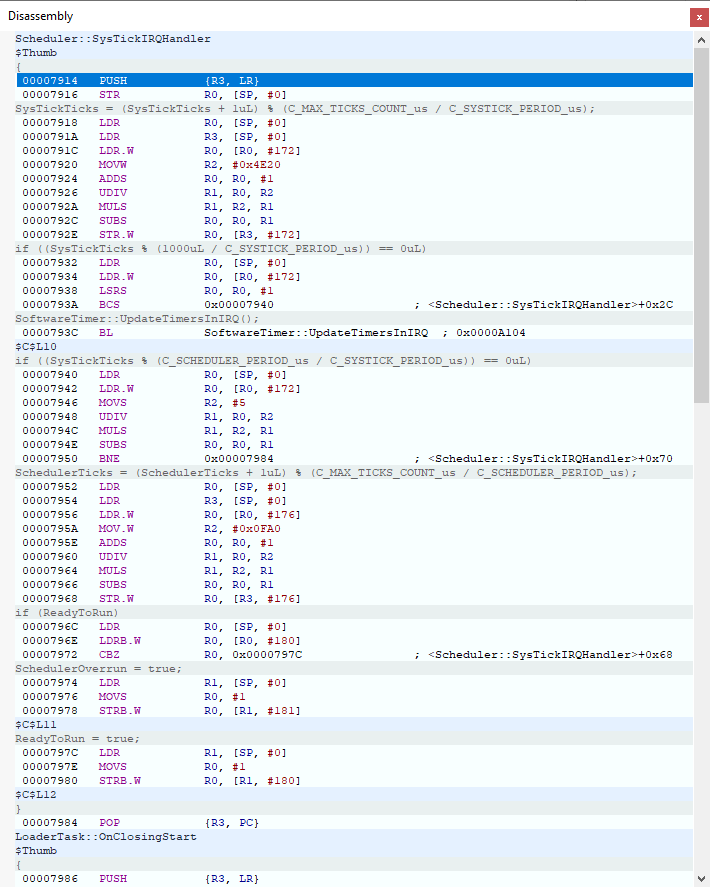
We invested in a J-Trace Pro for Cortex M and performed instruction trace and we observed the strangest behavior. At some pointer, in an interrupt handler, the PC does not simply increment after a simple register load instruction but jumps to a completely different section of the code.
Have you ever experience such a behavior ? Is there something in the errata sheet I might have missed ?
Please find below a screenshot of the instruction trace when getting in the hardfault handler: