Part Number: TMS320F28377D
-
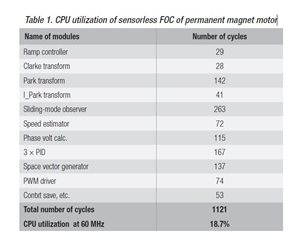
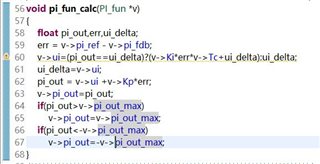
As for the calculation cycle occupied by PI, the official routine is

-
The occupied calculation time is
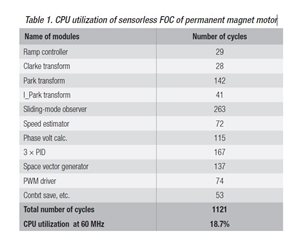
- As shown in the figure, a single PI calculation takes a total of 50 calculation cycles. In FPU, the calculation of saturation function takes about 40 calculation cycles. How can this be done?