Tool/software:
Hi,
We are using a MSP430FR5989 in one of our projects. We configure no wait cycles for FRAM access (NWAITS = 0).
FRCTL0_H = (UCHAR)(FRCTLPW >> 8);
FRCTL0_L = NWAITS_0; /* FRAM wait states: 0 */
GCCTL0 = !UBDRSTEN /* Disable PUC on uncorrectable bit error detection flag. */
| !UBDIE /* Disable NMI for the uncorrectable bit error detection flag (UBDIFG). */
| !CBDIE /* Disable NMI for the correctable bit error detection flag (CBDIFG). */
| !FRLPMPWR /* Disable FRLPMPWR while keeping FRPWR set */
| FRPWR; /* Enable ACTIVE mode. */
GCCTL1 = 0x00; /* All flags cleared */
FRCTL0_H = 0x00;
We are using 8 MHz for the MCLK, using the following configuration:
CSCTL1 = DCORSEL | DCOFSEL_3; /* 8 MHz */
Most of the devices works fine without any problems. But some few devices have been reset by a PUC. The problem have happened more than once in each device (2 or 3 times) but in the same few devices. When we read the System Reset Interrupt Vector (SYSRSTIV) to know the reset cause, all the times the reset cause is MPUSEGIIFG, except once that it was reset by ACCTEIFG access time error.
Reading the Recommended Operation Conditions in the microcontroller datasheet, it shows that for a MCLK at 8MHz, we can use NWAITS = 0.
Additionally, we reviewed the microcontroller errata document, implementing workarounds recommended for the possible issues related to the frequency deviations or for PMM configurations, as the recommended for CS12 and PMM29.
So, my questions are the following:
Is it possible, that for some devices, the factory calibration could be affected in such a way that the microcontroller ends up running at a little more than 8 MHz, and with NWAITS = 0 produce the PUC caused by ACCTEIFG?
Or it is possible that in some conditions, the device run at a higher frequency for a short period of time that also produce a PUC by ACCTEIFG?
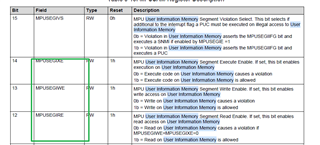
Finally, there is any possibility that this conditions could cause a memory protection violation (as MPUSEGIIFG), which is precisely the most common cause?
Thank you in advance for your help.