Tool/software:
For several years we have been running around 1000 units per month over a temperature from -40C to +85C. Our product has another main processor and the MSP430F5310 functions as a co-processor to provide a Real Time Clock (RTC). At five different temperatures we completely power off our product, which includes powering off the RTC (MSP430). At -40C we have around 4 units out of the 1000 that the RTC (MSP430) gets stuck and will not run. The number of four units fluctuates and sometime we don't have any that lock up. We have gotten around this issue by powering the MSP430 with a coin cell battery, so when the product power cycles at the cold temperatures the MSP430 stays running.
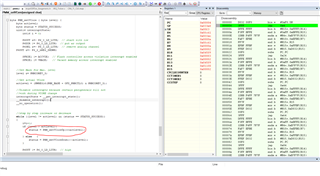
I have been determined to find this issue, with two failed units that have exhibited this problem I have reproduced at my desk by using cold spray... I have discovered that the program counter (PC) will zero when the code returns from the PMM_setVCoreUp function. I have attached a screen shot of the debugger and the unit stuck with the PC = 0x00004.. I believe that the PC gets completely cleared then runs to the 0x00004 where there is an infinite loop jumping to the address 0x4 as shown in the snippet.
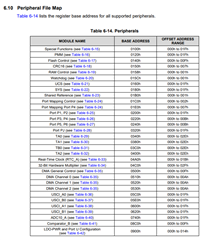
What peripheral is a address zero? Is address zero in flash and is it possible to write code to produce a POR when this condition happens? Note the User NMI flash access violation or bus error didn't catch this out of memory error.