


I'm going to refer to this previous post I started earlier. I am trying to communicate to an SPI master using a MSP430 FR5739, specifically, act like an serial memory device for the SPI master. Right now, I am trying to process an EEPROM read instruction from the SPI Master correctly, but the way I've configured the MSP430 has proven to be too slow. Below is an example of how the SPI processes a EEPROM read instruction.
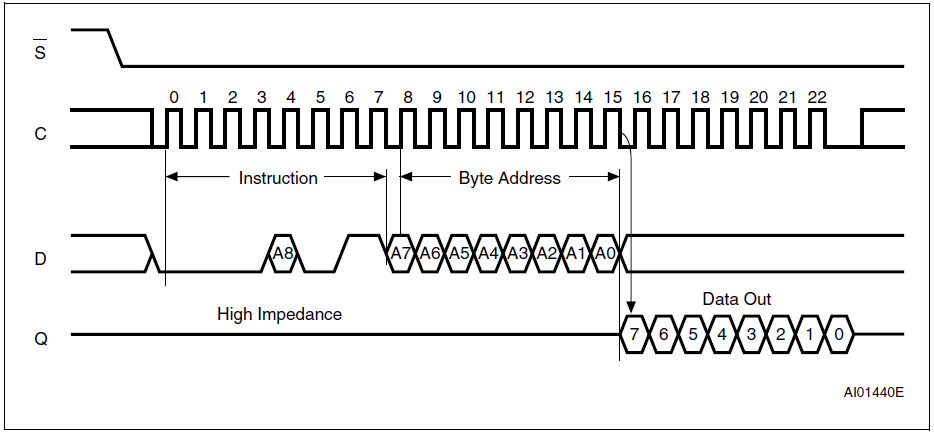
In the picture above, D is the MOSI, and Q is the MISO. The SPI master sends and receives data in sets of three bytes (making 24 clock cycles in total). The first byte is the instruction to the SPI slave (or the MSP430) to read an address from the EEPROM. The second byte is the address it wishes to read from. Then, after the 16th clock cycle, the SPI master will expect to begin reading the contents in the specified address of the EEPROM.
Therefore, what I will need is for the MSP430 to respond quick enough so that between the 15th and 16th clock cycle, the MSP430 will be able to capture the data in a certain address from the memory, and store it in the transmit buffer for the SPI. I currently have an SPI ISR in place so that it can acquire the data aas quickly as popssible. I am doing this repeatedly, so I think DMA may be useful. Does anyone have any suggestions?


