Other Parts Discussed in Thread: MSP430F5419A, TPS5420, MSP430F47187, MSP430F5438A, MSP430F5418A
Hello there:
Since year 2000 I’m working with many families of MSP430 and I never before faced such problems like now. This is my first project using F5419 and the MCU’s behavior is erratic.
After read the errata sheet, I thought that it could be a general fault on “non A” MCU’s versions. After this, I changed from F5419 to F5419A and the stability is better but not satisfactory.
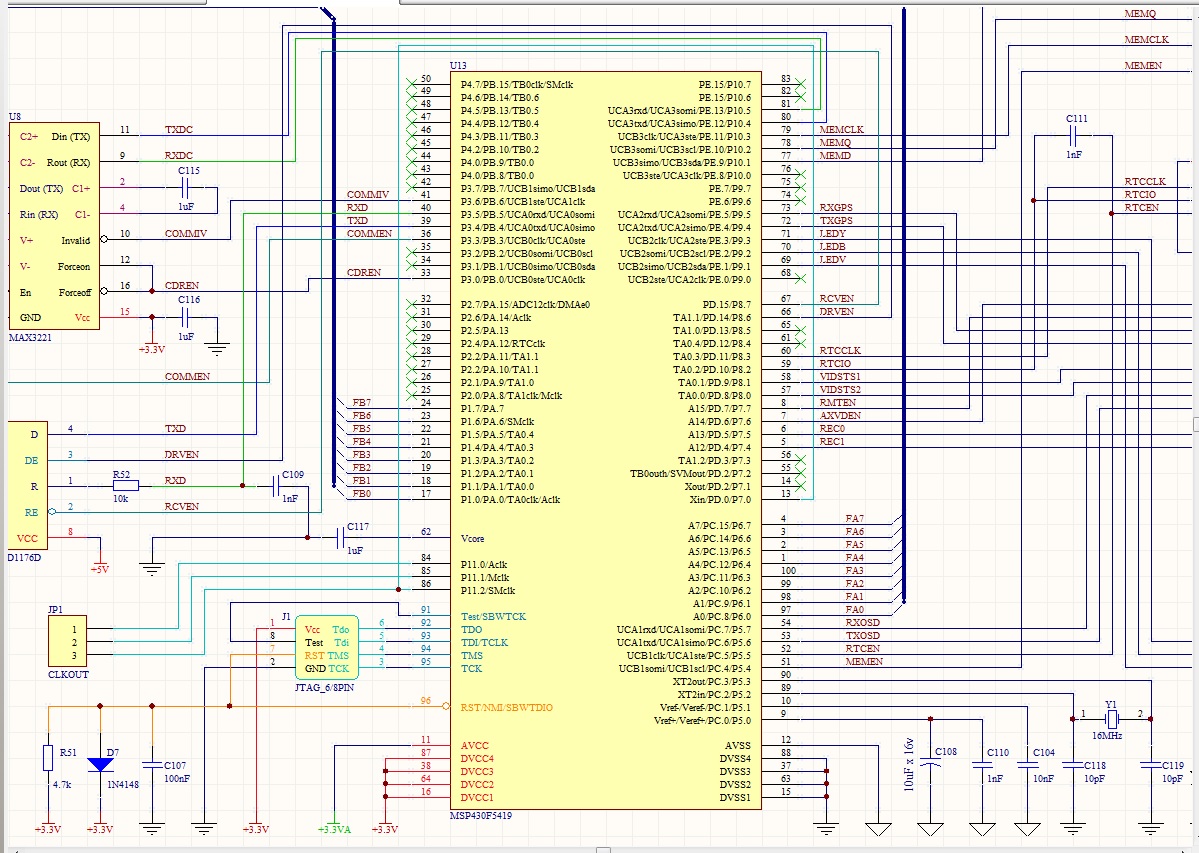
Basically, the system is a pair of PCB’s where a local unit (using a F5419A) communicates via RS485 with a remote unit (using a F149). The local unit also uses a keyboard, a RS232 GPS, 7 channel ADC, a rs232 serial controller OSD (on screen display), an external RTC, a 8MB external EEPROM… and so, it must handle constantly with all those resources. This system is used for remote control/telemetry. All code was developed in assembler using IAR.
Detected issues:
- Missing PC during program execution:
The MCU seem to be extremely sensitive to ESD or noise. By example; if I touch the GND plane with a metallic object, CPU hangs because PC jumps anywhere. I added a routine to “catch” a “vacant memory access” event using IRQ’s and adding a breakpoint on that IRQ service routine I noticed that usually, the return address on the stack points to 00000h and rarely to other address far from main code memory. An “ugly” workaround was to generate a “partial reset” of the application jumping from this IRQ routine to the main loop after reinitialize stack and IRQ’s. (really ugly workaround, but it helps to handle about 90% of cases)
This situation is only triggered when I touch a GND plane with a metallic object or when I generate an ESD noise with a fluorescent light. It never happens if I leave the system running for hours or if I use menus or control functions. The ground plane was checked and is consistent, and enough decoupling and filtering is provided for the MCU and peripherals.
From my experience with MSP430, I never before saw such sensibility to noise.
- Missed or wrong code lines at device programming:
This is really strange because I never before saw something like that. After program a device sometimes it presents a wrong program flow (like if removing code lines).
Specifically; if I press the button to enter in the configuration menu, the system goes inside the menu and jumps out instantly. This happens “always”, no matter how many times I reboot system. But, if I re-program the MCU with the same code, the program flow is normal. (I mean, if I press the button to enter to config menu, system goes inside menu and stay there as it should be)
I have seen this fault about 4 times during the development process, and always in different program parts.
As additional information: previously I was researching about those issues with Mr. Michael Stevens (from TI customer’s services), he checked PCB design and schematics and agreed that all was ok. Reset circuitry, decoupling, filtering, etc… We agreed that after build a second prototype I was going to contact him again to give a follow up. But unfortunately, I was derived to this forum and I have to expose the issue again from the beginning.
So…. any Idea?
Thanks.
Miguel