Other Parts Discussed in Thread: MSP430F5335
Hello Team,
I am currently having a strange problem with my application on the auxiliary board MSP430F5335 crashing. I am running FreeRTOS v8.2.2 on an MSP430F5335 based board. I am using IAR v6.30.3. It is a relatively simple application which acts as an i2c slave device and provides analog outputs. A separate i2c master device controls the analog outputs.
I have been working on adding firmware update support where the master i2c device can update the firmware in the MSP430F5335 slave device. The first thing I did is implement the part where I send down the image. Right now, I am simply sending down the firmware in 128 byte chunks over i2c and getting back a 8 byte confirmation message for each chunk. The 128 bytes are stored in a RAM buffer. I actually use a 512 byte RAM buffer. Eventually, once I have 4 of these 128 byte chunks, I will program the 512 byte chunk into the flash memory in the MSP430. Right now though, I am only storing in the RAM buffer in my testing. The master does this repeatedly as fast as possible to send down a total of 0x10000 bytes in the firmware image.
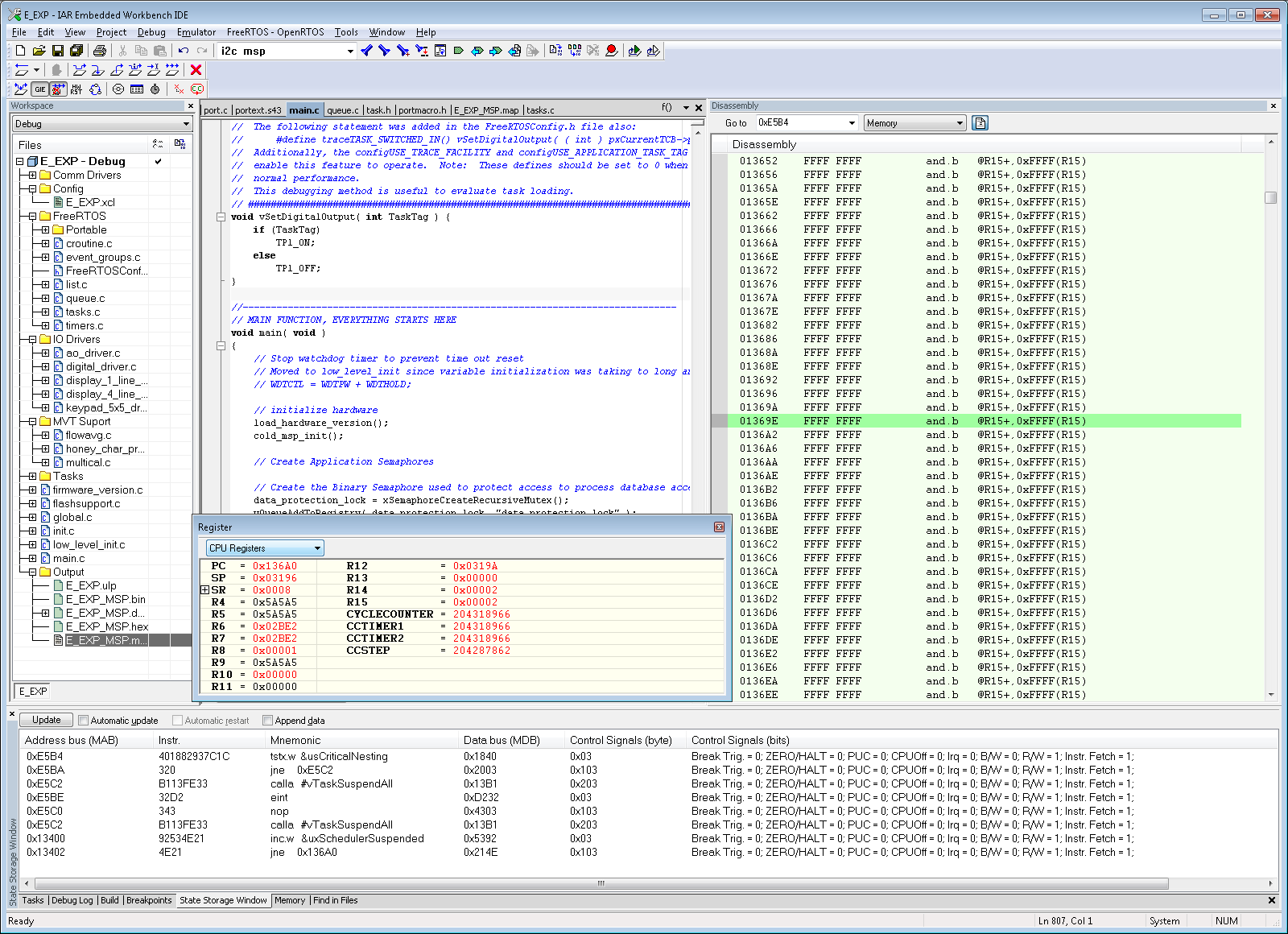
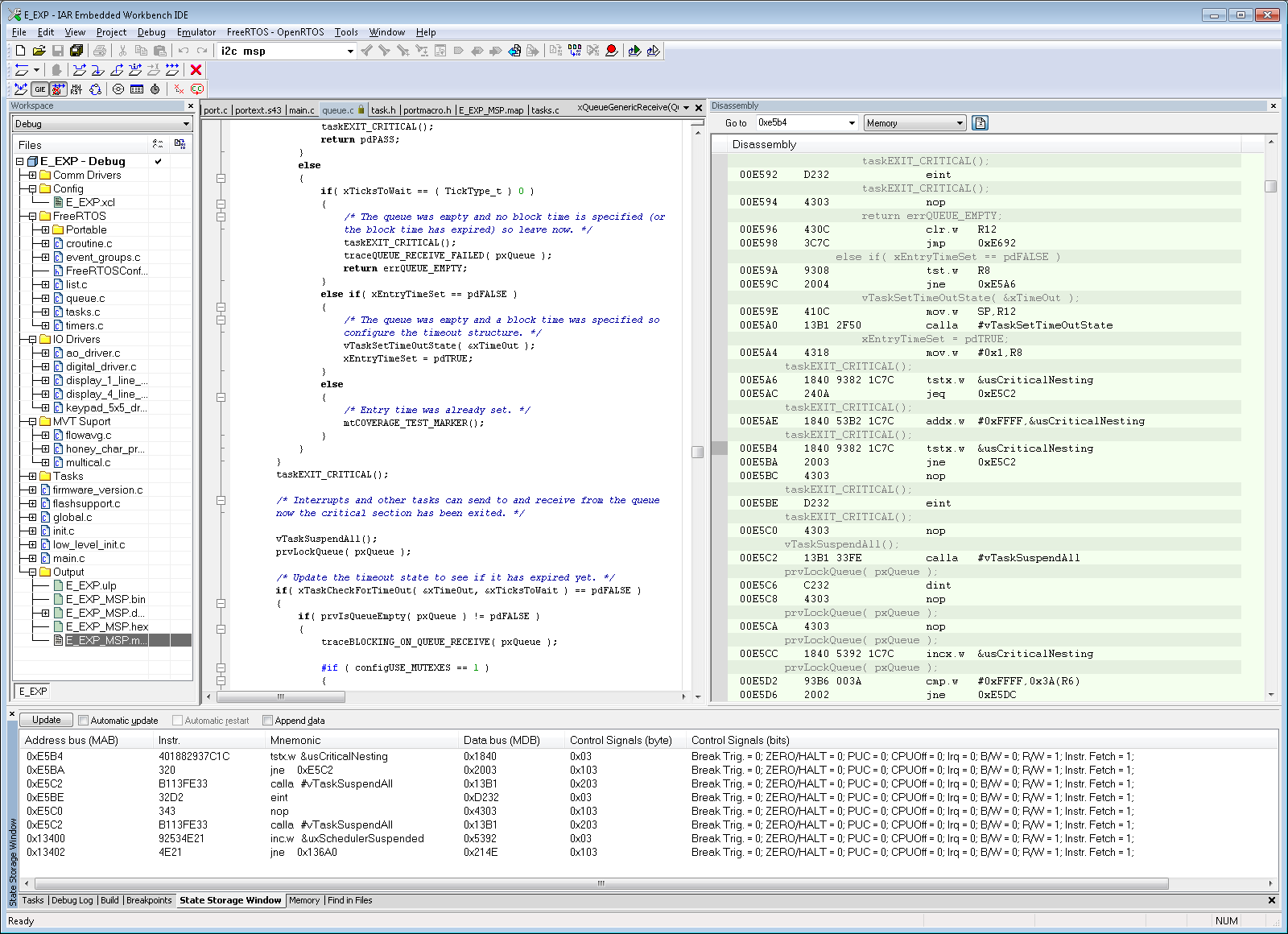
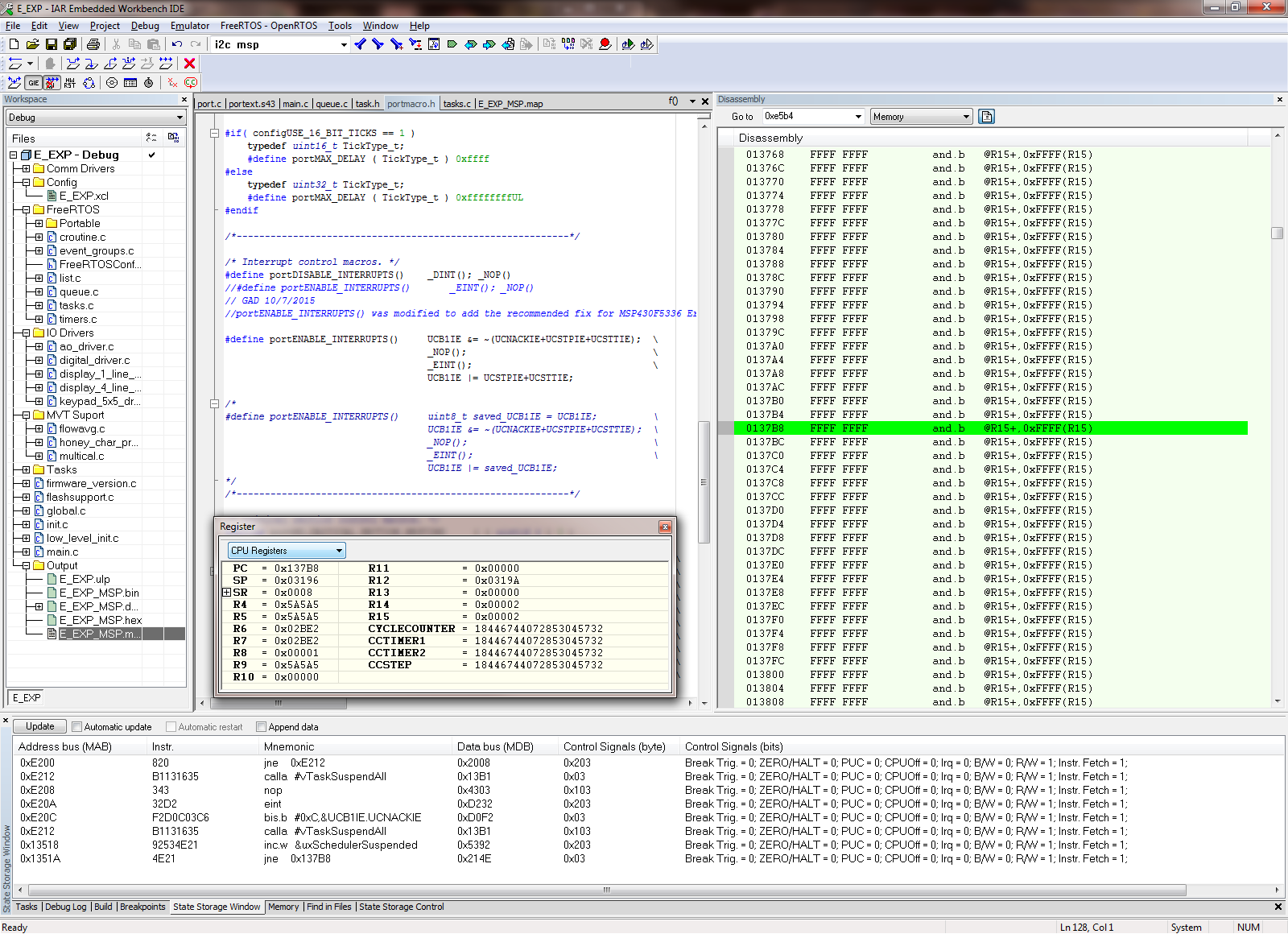
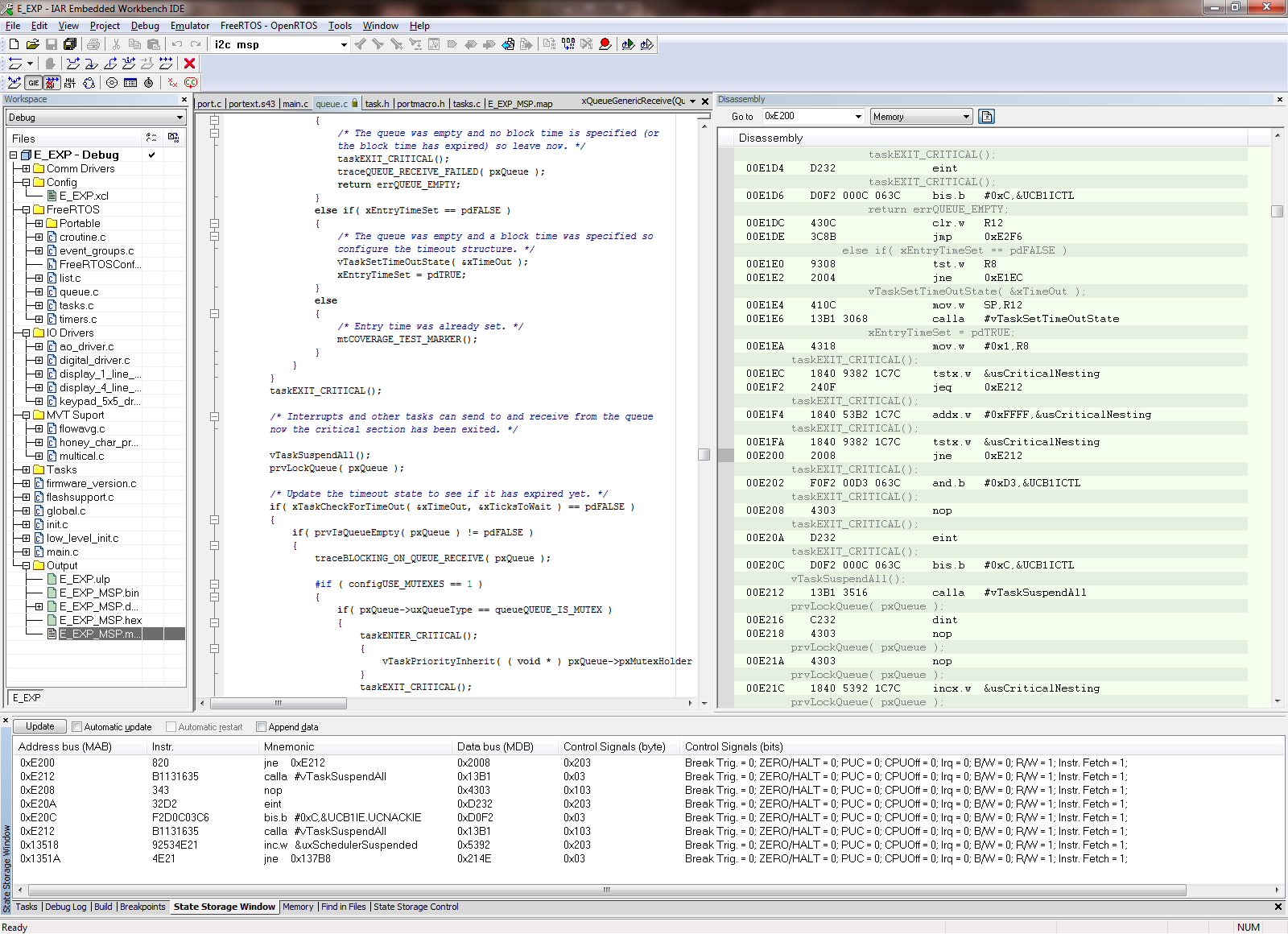
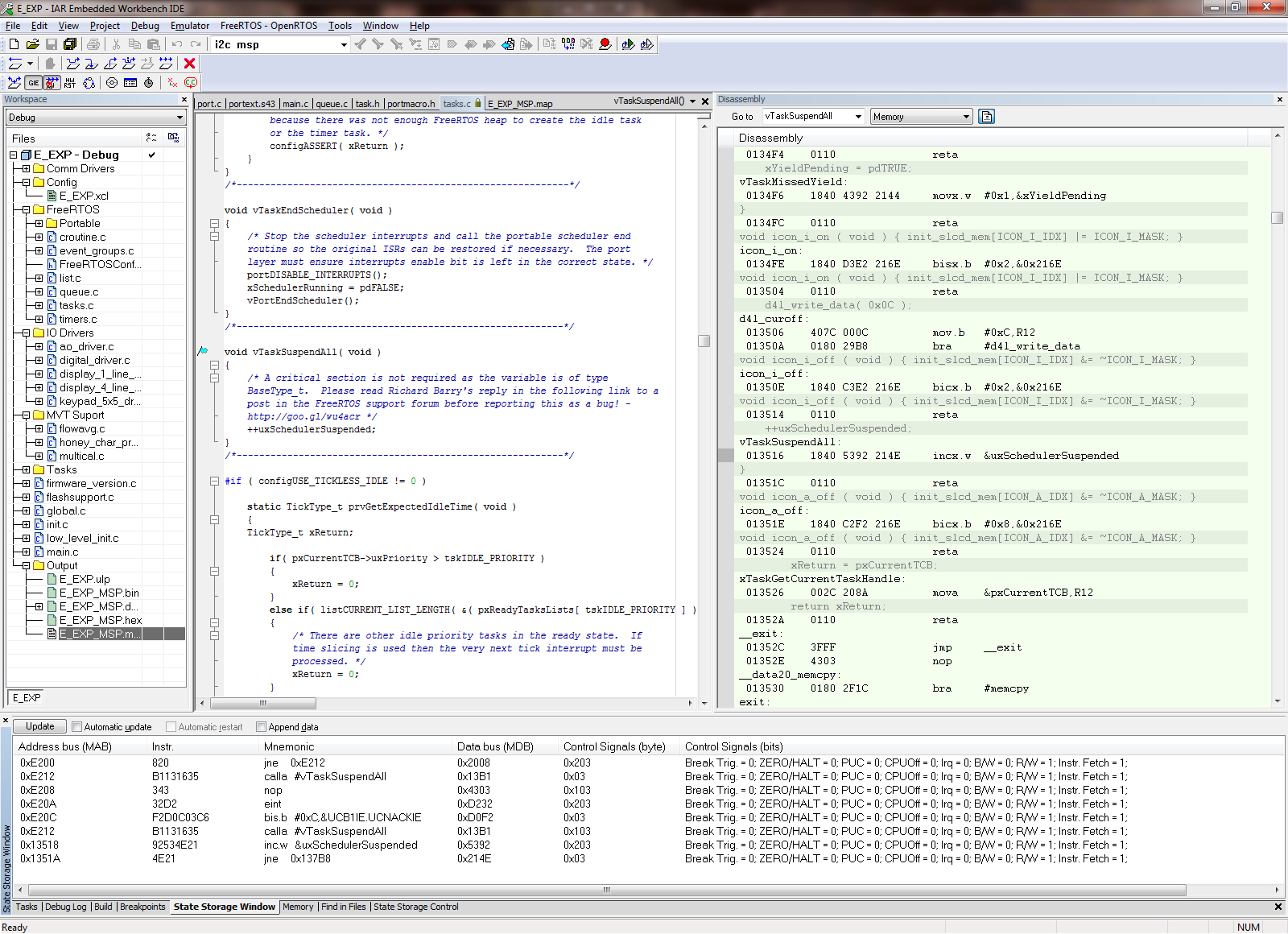
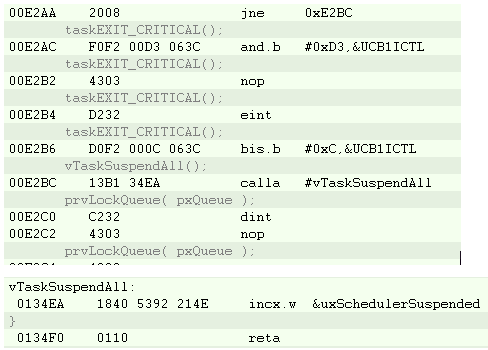
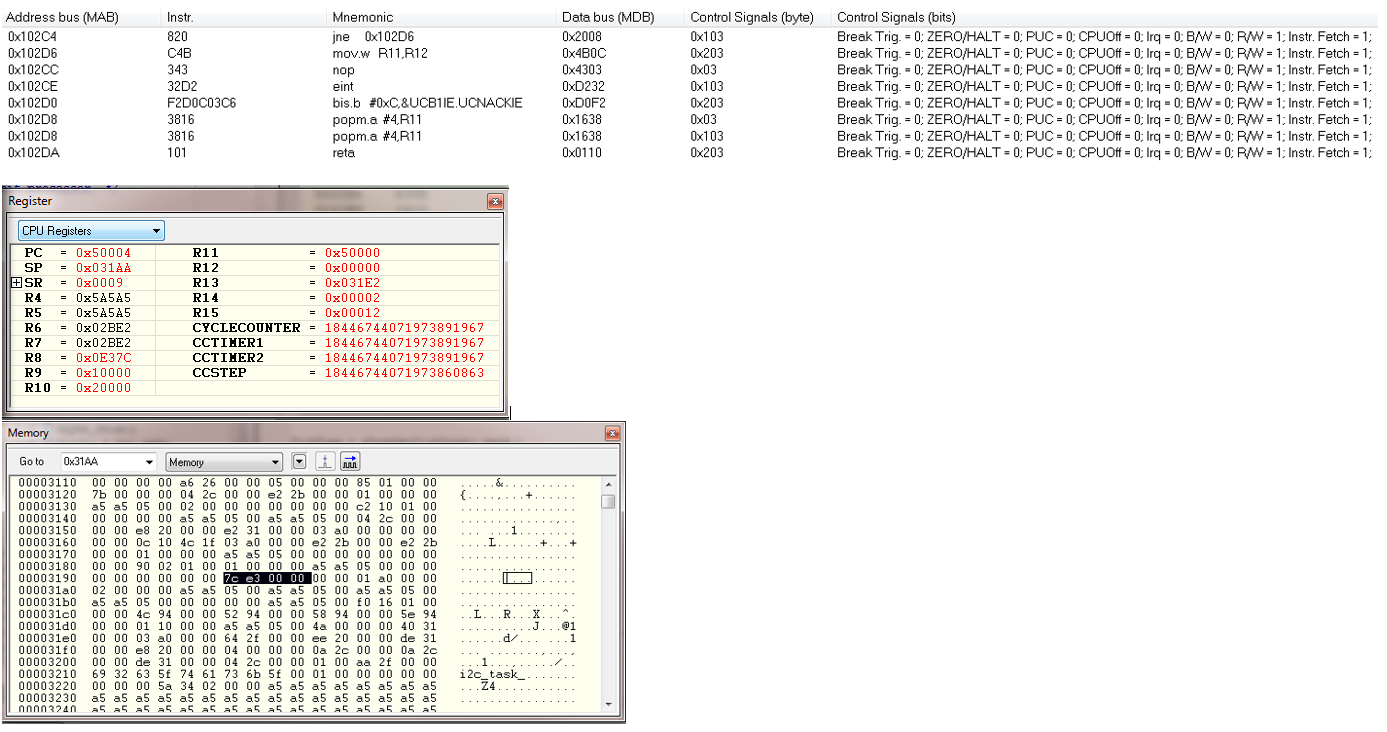
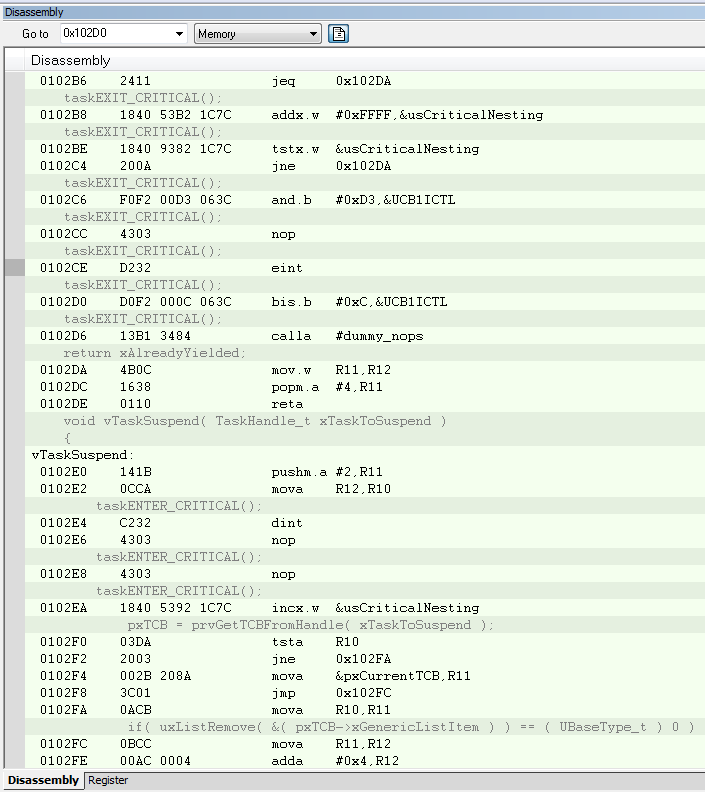
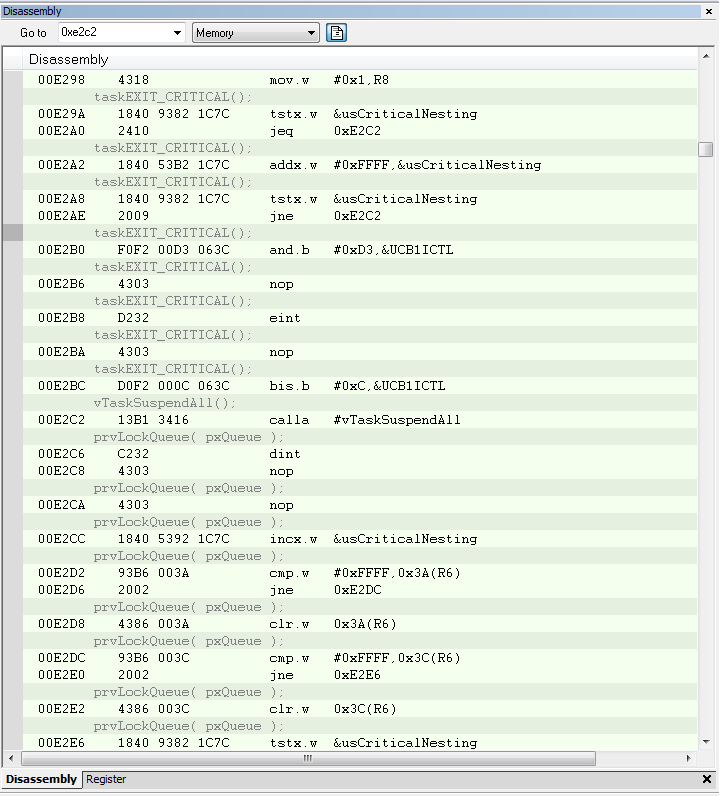
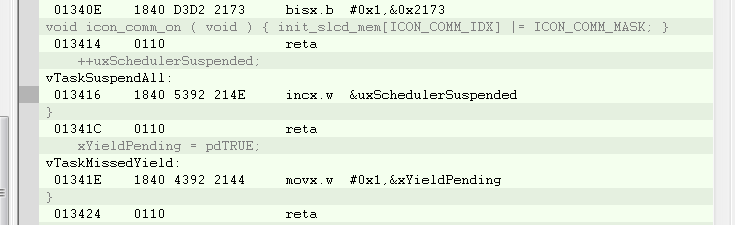
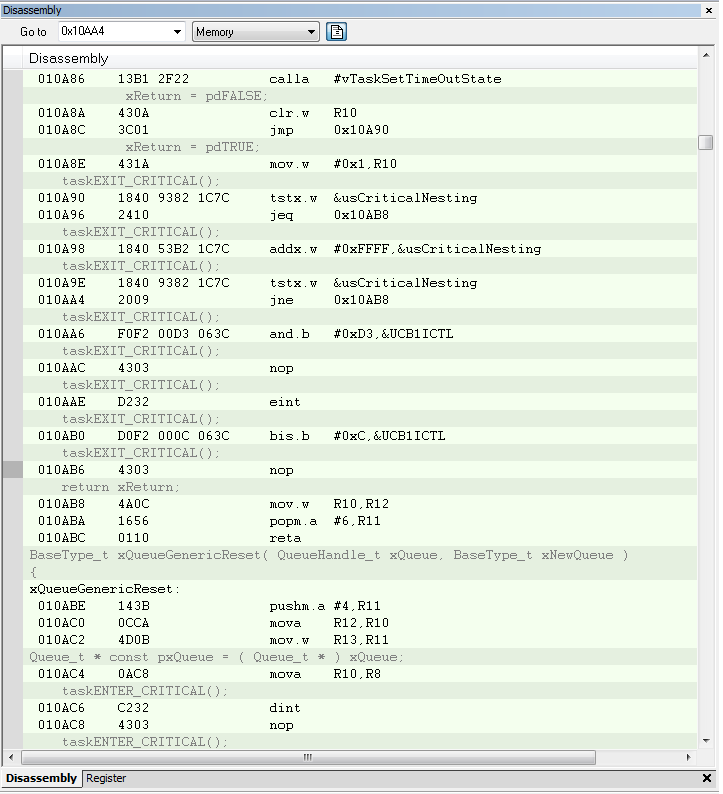
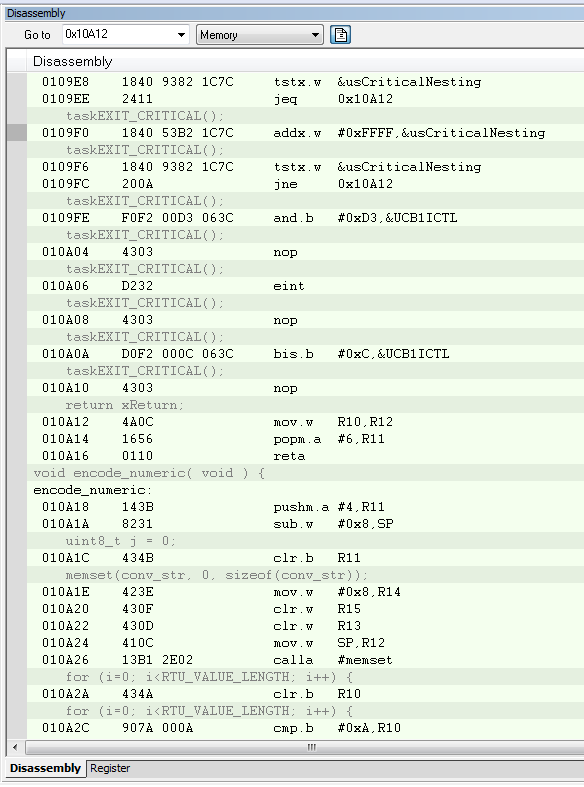
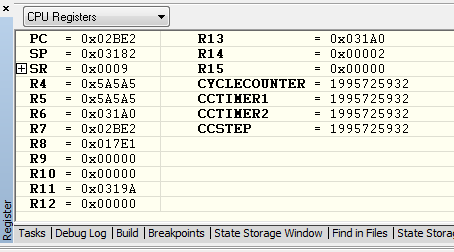
I am using the i2c interrupt service routine to trigger a message processing task by calling xSemaphoreGiveFromISR when a complete i2c message has been received. portYIELD_FROM_ISR is called at the end of the service routine. The MSP430 application is crashing at random times, sometimes on the first i2c message and sometimes after many have been processed. Using the State Storage window in IAR CSpy, I set advanced triggers to break on address bus instruction fetches outside of the actual program memory space. The best I can tell, the crash seems to be occurring when xQueueGenericReceive calls VTaskSuspendAll on line 1496 in queue.c (FreeRTOS) code. It looks like the CALLA instruction jumps to 0x13736 instead of 0x13734 like it should. You can see the difference in the attached screen shots “Crash” and “Normal Operation”. From the State Storage Window you can see were the CALLA jumped to 0x13736 during the crash instead of 0x13734 like it did during the normal operation screen shot. When the jump is made to the wrong address, a “jne 0x1393A” is executed instead of the normal RETA instruction that should occur. 0x1393A is an invalid address which is outside of the actual code image. That is what triggered the breakpoint. I have not used the State Storage Window much in the past so I don't have much experience with interpreting the results. I could imagine with the 2-stage pipeline it may be somewhat deceiving at times. I have attached a screen shot of CSpy with the information during a successful normal call and also when the crash occurs.
I have been searching the internet info for possible solutions and have tried many things to solve the problem. Finally late last night I found something that seemed to fix the problem. I changed the optimization settings in IAR from "none" to "high, balanced". I set up the i2c master application to continually send the 0x10000 firmware image over and over and the MSP app ran all night with no problems. I have been running the code with optimizations set to “high, balance” for the past week or so with no problems at all. I changed the optimization level back to none today just to confirm, and immediately started seeing the problem again.
I wonder if the problem has to do with the CALLA and RETA. I have seen several issues that occurred while creating the MSP430X port for FreeRTOS, but have not really seen in reports of issues with recent versions.
Any ideas on why setting the IAR optimization level to "high balanced" would have solved the crashing problem?
Any ideas on how to fix the issue with the optimization level set to none would be greatly appreciated. Debugging is much easier when set to none. In addition, I really need to understand exactly why this is happening to make sure my application will be reliable long term. Setting the optimization to high may only be masking the problem. It may still occur with extensive long term testing.
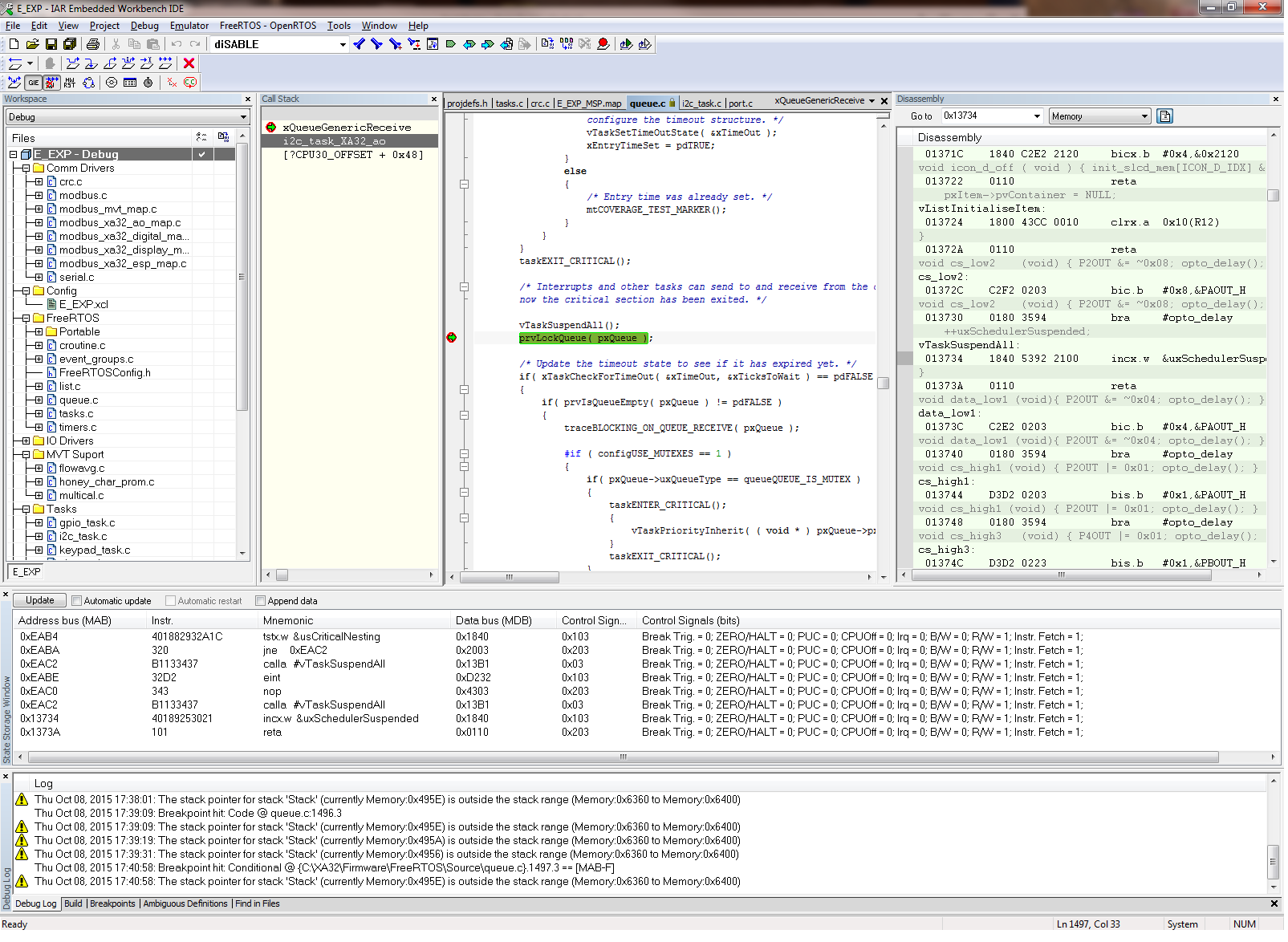
Normal Operation Screenshot
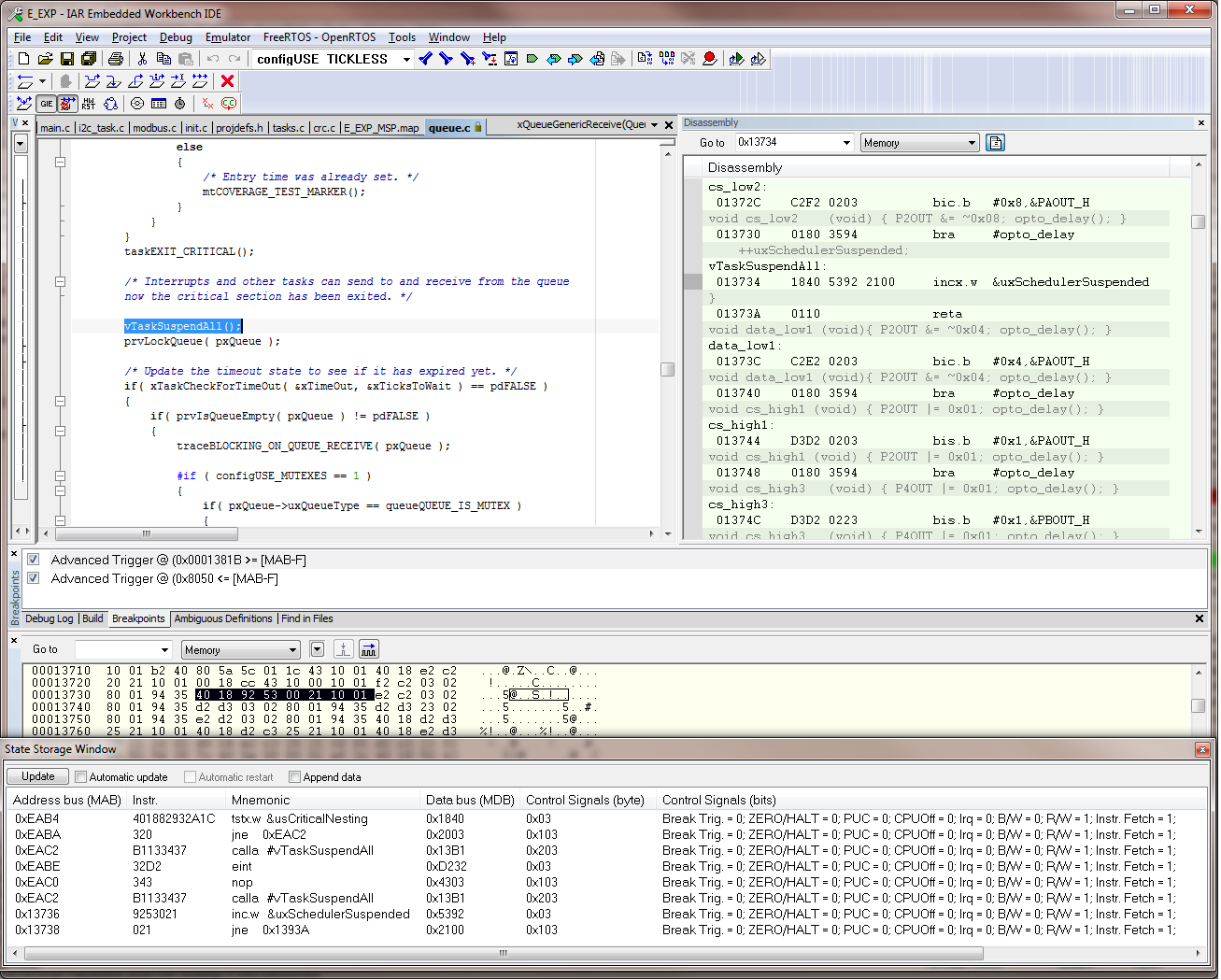
Crash Screenshot
Thank you and I appreciate the help!!