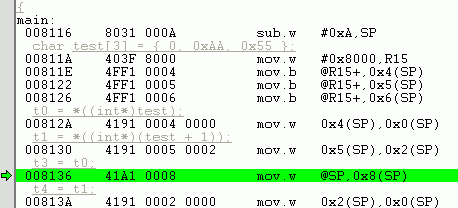
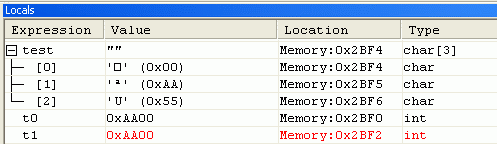
I need a way to align a structure with CCSv4; I'm performing a large code port with structure that have been defined using a place holder that will allow me to byte align on the structure. For example,
typedef struct {
unsigned int a;
char b;
} BYTE_ALIGNMENT_PLACE_HOLDER my_struct_t;
where BYTE_ALIGNMENT_PLACE_HOLDER can be defined based on the specfic platform/compiler used.
DATA_ALIGN appears to work only on the variable instance of the structure; is there another command or a simple #pragma that can be used, rather than having to update 100's of files that use the structures?
-meb