Hi Support,
We have little problem I would love to get your input and expertise on MSP430 microcontroller (MSP430F5529A)
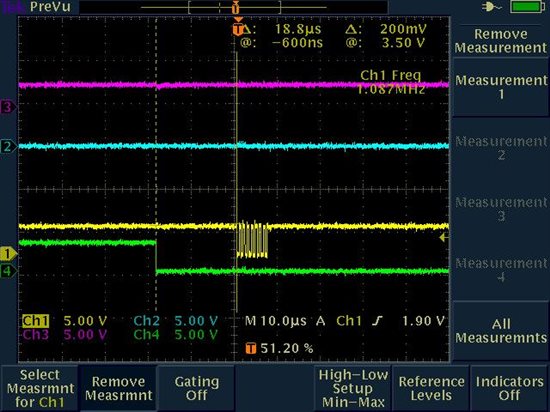
I am attaching 2 snap shots TEK00011 TEK00012 (the same image in deferent zoom )
As you can see MSP SPI in GPIO Chip Select get delay from the moment of getting the Chip Select to “0” the clock is delay until 18uS – and we need to have only delay of 1 uS
Other wise the slave is not detected the connection as SPI – do you have any idea to solve the problem thanks