Part Number: MSP430FR5994
Other Parts Discussed in Thread: MSP-EXP430FR5994, , MSP430F6659, MSP430FR2633, MSP430FR4133, MSP430FR5969, MSP430FR6989
Hello all,
Hardware : MSP430FR5994 LaunchPad Development Kit (MSP-EXP430FR5994)
CSS compiler : CCS Version: 9.3.0.00012
CPU : 78C85QW G4 / MSP430FR5994 / REV C
More detailed information about the setup, in the attached project.
I have this very strange prolem related to a simple tick counter I've implemented for MSP430FR5994.
Setup is very simple, I'm starting a timer (TA2) with interrupt (on CCR0). Inside ISR I just increment a counter (UINT64).
When I need to get counter value from main code, I disable interrupts for that specific timer and get the value.
Afterwards I re-enable interrupt for it.
Long story short : this causes wild execution of code, hangs, and all sorts of similar problems.
And I don't have any rational explanation for all of this. Already checked errata, family datasheet, datasheet, forum post etc...and I can't find any reasonable explanation.
The only closest thing that I can find is in MSP430 family user guide, section 1.3.4.1 Interrupt Acceptance, where there is a note on enabling/disabling global interrupt flag.
But this is related to global inerrupt flag, which is claimed as fixed when using compiler intrinsics __disable_interrupt()/__enable_interrupt() (not tested/checked explicitly).
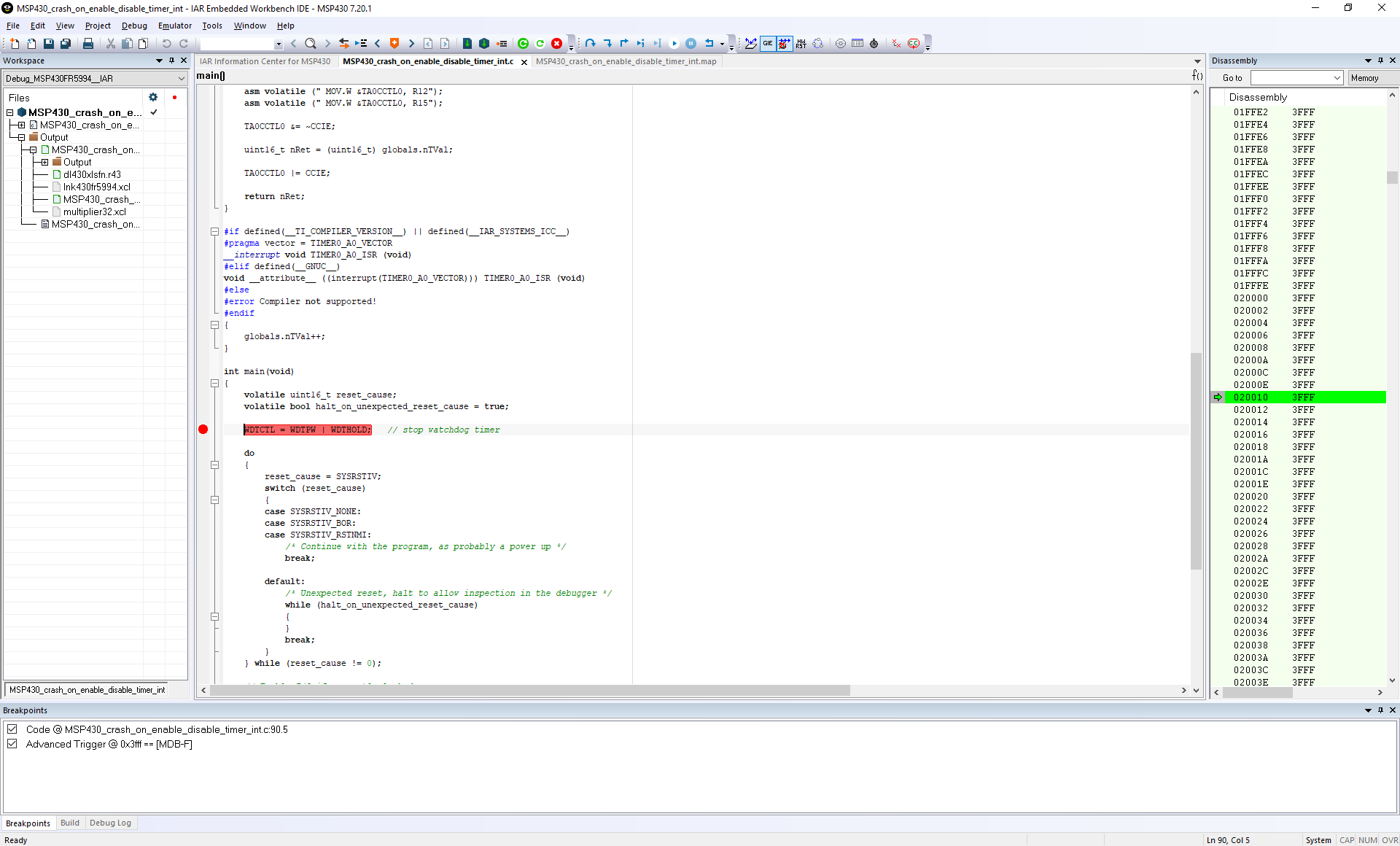
After 3 days fight with my large project, which suddenly start to reset the device after adding some variables, I've managed to boil-down the problem to a simple test project.
I've already checked assembly code (seems quite ok), linker map file (sections seems ok, stack is not overriden by my value) and anything else I can think of.
I'm attaching it in this thread. In the begining of main.c, there is more detailed description of setup/build/used devicess & revisions etc.
Entire test case is in main.c, supplied with proper comments. Other files are just supplementary for initializations etc.
I know this sample project have logical problem related to reading correct counter value (because of instruction pre-fetch mechanisms inside CPU),
but this should not cause any of observed effects.
So test project is setup to blink the green led if everything is currently working, and to turn on the red one if improper reset is detected.
Led blink may hang, this also indicate a problem, long WDT (~ 40 sec) is also setup, so device will reset eventually and red led will be turned on.
Depending on conditions, problem appear right away (no led on) or after short time (1 - 10 sec).
Also a startup delay (4 sec) is in place so if there is reset of any kind it will be visible with naked eye.
Dev board reset button will clear red status.
If initialization fails, device will hang forever (no WDT reset), so this is also easily detected.
It is very easy to test and see when the problem appear, no need for debugger or any communications attached, that may affect the test.
The related "things", that affects whether this problem will appear and how, according to my tests are :
- Counter position in memory.
- Size of counter (UINT16/UINT32/UINT64).
- Various NOPs (or else) placed arount function that gets counter.
- Various NOPs (or else) placed inside ISR.
- Removing desable/enable interrupt makes problem disapear (check main.c comments)
In general my problem is not with the problem itself, but with lack of information about it.
I'm using other "lock-free" techniques in various parts in my code, and if such undocummented problems (?) appears now and then, I can't really trust this CPU.
So my questions (finally) :
- Solving this particular problem is apparently easy, by just adding simple NOP between disable interrupt and reading counter value in main code. But is it correct ?
- Are other peripherals have same problem ? What is their solution ?
- Is there any other place except errata document & forums, where such problems are described ? Where ?
I'm involved in a very serious project, and I can't afford any hidden "surprises" in the final product.
So please advise.
Thank you for your support,
FilipCrashTest.zip