Other Parts Discussed in Thread: MSP430FR5989, MSP430FR6989
Hi,
I´m having an unexpected behaviour signaled by MCLK, working with a MSP430FR5989EP Rev.E, that I need to better understand before designing any workaround.
Context:
The microcontroller periodically receives an asynchronous SPI communication in 4-pin slave mode that represents a status message from the master.
The SPI reception triggers DMA1 module configured in single mode byte transfer to move each of the N received bytes (status message has a known fixed length N) from UCB0RXBUF to a buffer in RAM (incrementing destination also as byte), to be processed in main routine after the DMAIFG is raised.
The microcontroller's main loop periodically waits in LPM3 mode for a TimerA0.0 interrupt while SPI reception can occur, and many times the TimerA0.0 ISR overlaps with SPI reception without problem.
But there is a specific scenario, that makes DMA module to lately transfer a byte of such status message.
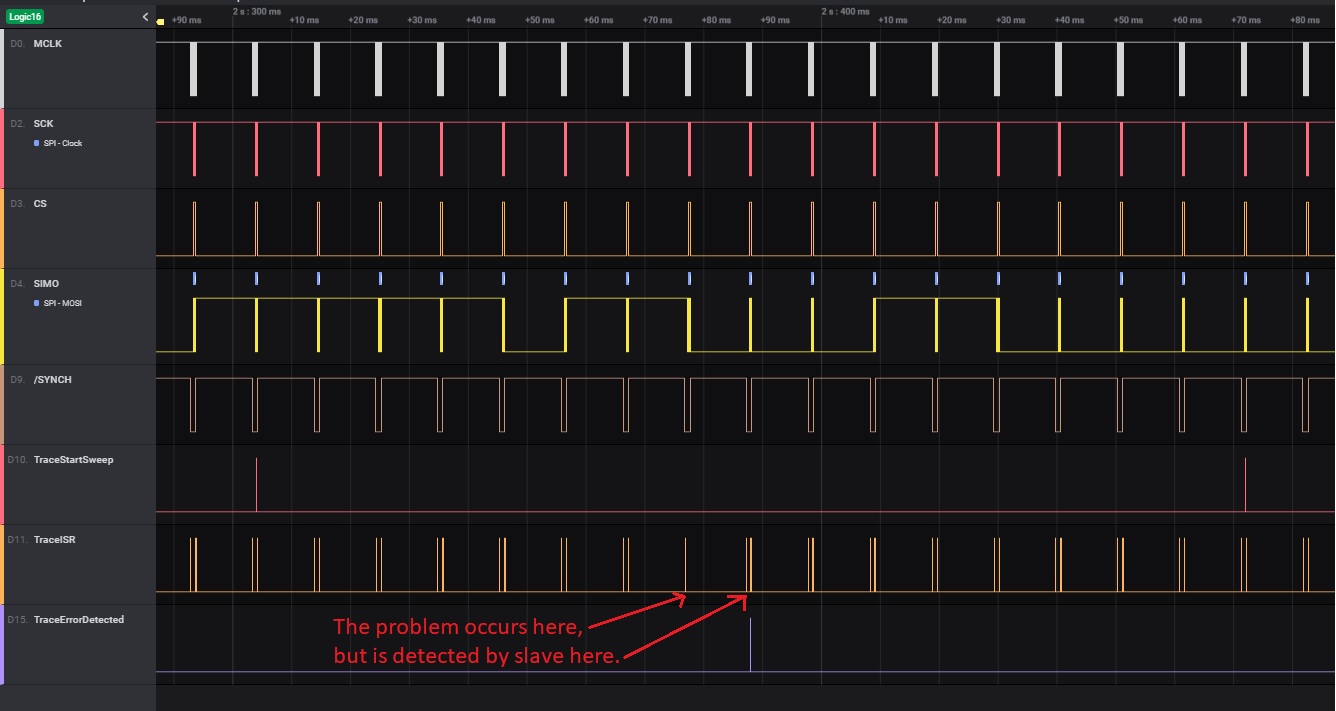
The following picture (PICTURE1) is a capture of the SPI reception (SCK and SOMI signals) attended by DMA module as short MCLK signal bursts (0.625us width) approx. 5us after the 8th risig edge of SCK, that overlaps with execution of the main routine attending Timer A0.0 interrupt and returning to LPM3 (TRACE1 signal).
PICTURE1: https://drive.google.com/file/d/1_sZtCb4t-Eim0TyWaygotPmCtsETUFln/view?usp=sharing
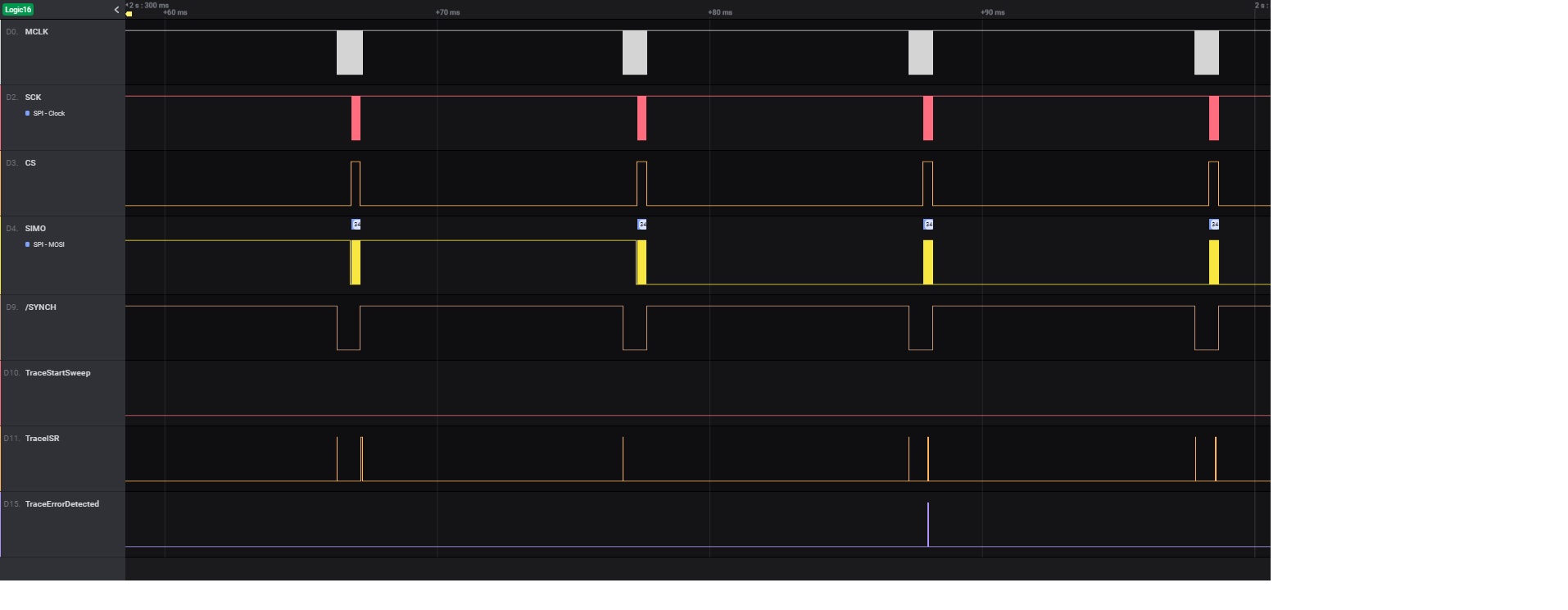
Next picture (PICTURE2) is a zoom of same capture with timing markers in the capture region where I want to focus.
Timing markers 0 (red) and 1 (green) measure the 5us delay from SPI RX trigger to DMA transfer.
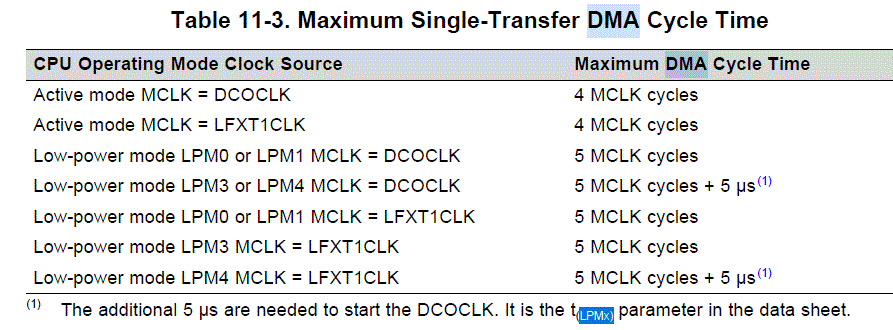
This 5us delay I understand is the one described in MSP430FR59xx User´s Guide (SLAU367P) section "11.2.7 DMA Transfer Cycle Time", to turn on and sincronize with DCO.
PICTURE2: https://drive.google.com/file/d/1qc81qf2zQKgUprw3TGEE1_1P66BQA4Rj/view?usp=sharing
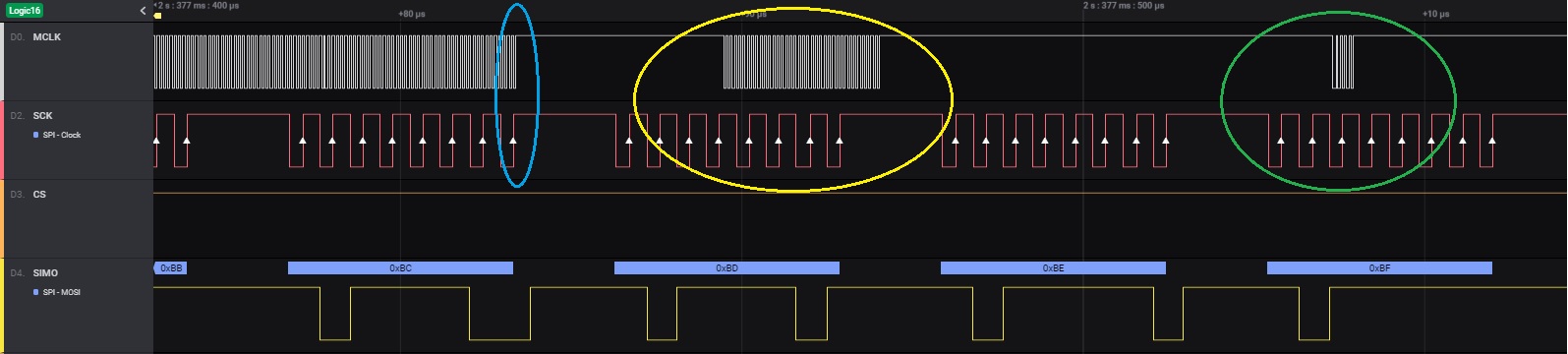
The problem I´m having occurs when main routine returns to LPM3 just when the SPI RX trigger occurs (8th SPI clock) as ilustrated in next picture (PICTURE3, larger zoom of PICTURE2).
PICTURE3: https://drive.google.com/file/d/1YpIOWE4wpv1D9PGfRybSAZWmq4q9fduA/view?usp=sharing
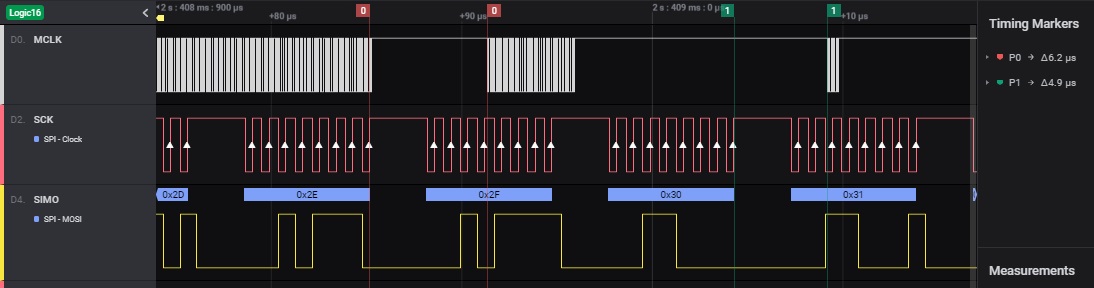
The MCLK signal becomes active for approx. 5us or 6us (timing marker 3, orange) for DMA transfer of 2 received bytes (the pending 0x9A byte and the just arrived 0x9B byte), while a single byte transfer takes 0.625us (see timing marker 2, purple).
The problem is that many times this scenario is observed, inspecting the RAM buffer (DMA destination), the 2 bytes transfered bytes by DMA, have the value of the latter one, 0x9B in this case.
The processing of the RAM buffer (destination of DMA), confirms that the position for byte 0x9A has the 0x9B value, and position of byte 0x9B has 0x9B value as expected (the status message issued for this test was forced to a incremental sequence to aid in problem detection at the slave microcontroller).
As the 0x9B value is present in UCB0RXBUF by the time of the 8th SCK rising edge, I conclude that the 2 DMA transfers occur by the end of the 5us/6us burst of MCLK (timing marker 3, orange).
In some cases, when inspecting the RAM buffer, the byte sequence buffered is shifted as if it had lost the 0x9A trigger: it doesn´t contain the byte 0x9A and the 0x9B byte is not repeated, seems like the 0x9B byte trigger for DMA has overriden the 0x9A byte pending trigger.
Considering the observed scenario and that:
- I have no other interrupts involved (I confirmed that, setting another trace signal inside all ISR´s for the rest of Interrupt Vector entries, and none of them occurring here)
- No FRAM access is involved in these DMA transfers
Questions:
Can the extra MCLK burst time observed in timing marker 3 (orange) be explained by any microcontroller hardware artifact ?
Could you confirm that the 5us delay described in section 11.2.7 correspond to the one observed by timing markers 0 (red) and 1 (green) ?
Could the errata CS7 be related with this problem ? (although the observed MCLK burst is at 8Mhz as expected)
Additional comments and information:
- MCLK and DCO are configured at 8Mhz ( CSCTL1 = DCORSEL | DCOFSEL_3; ) and SMCLK is configured on with a divider of 2 (4Mhz).
- I configure DMACTL4.DMARMWDIS bit in 1, but the problem is also observed setting it to 0.