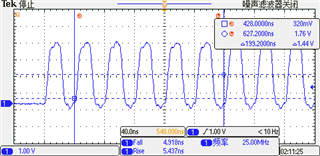
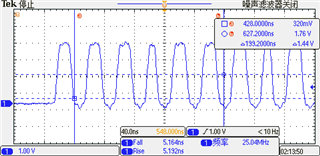
Hello,
Does the ICSSG1 PRU0 supports assembly instruction like DMB, DSB and ISB? The doc PRU Assembly Instruction User Guide does not mention the three instructions.
Where can I find how many instruction cycles each of the PRU assembly instruction costs? Such as SBBO, LBBO?