


I trained the model of edgeai-yolov5 and got the prototxt file and the onnx file with the new export.py. After that, I complied the onnx model file to a int8 bin file and a float32 bin file. I run these two bin file with the PC_dsp_test_dl_algo.out file in ti-processor-sdk-rtos-j721e-evm-08_01_00_11/tidl_j7_08_01_00_05/ti_dl/test, and found bin file of float32 can't get the right result.
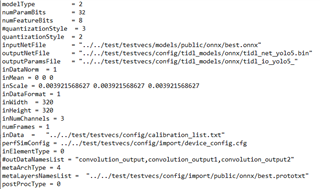
The following picture is the import config. In the file, I set numParamBits = 8 and run tidl_model_import.out to get the bin file of int8
The result of float32 inference



The result of int8 inference



It can be seen from the picture above that the inference result of the float32 model has no rectangle found. Is there some thing wrong with my config file? Why the bin file of float32 can't get the right inference result?
Here is the import log of float32:

Because I will use the model of int8 in TDA4, is the above import config file right for the int8 bin file?

{kind=link}