Hi,
I am facing an issue while I am running my custom model on my board. I am using a TDA4VM-EVM with the SDK : PROCESSOR-SDK-LINUX-SK-TDA4VM_08.01.00.02 | TI.com
I am currently trying to develop an image classification model on my own on tensorflow, this model is based on Conv2D, Maxpooling2D, Dropout, Flatten and Dense layer with relu and softmax activation.
In order to have a compatible environment with my computer and my EVM I am working on the edgeai_benchmark : GitHub - TexasInstruments/edgeai-benchmark: EdgeAI Deep Neural Network Models Benchmarking
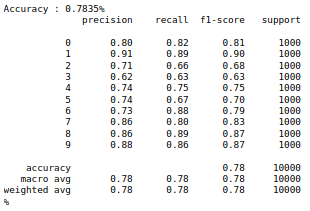
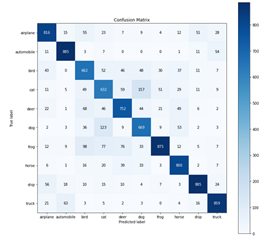
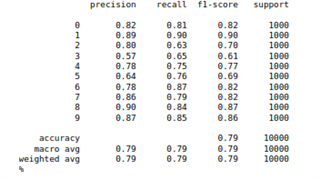
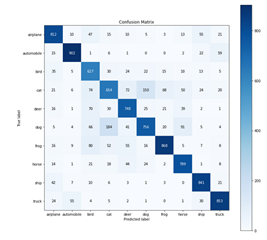
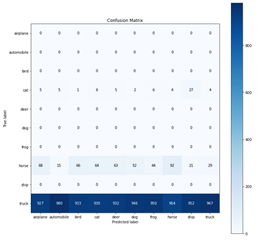
I succeed to run my model on ARM with great performance (~80% of accuracy similar as my computer accuracy) but while I want to run my model on MMA the accuracy drops to 10%. Why this behaviour happened?
Currently, I am training the model on my computer and I tried with different ways to save my model (from_saved_models / from_keras_model) is there a recommended way to save my model and is there optional parameter to activate while I'm saving my model ?
Best regards,
Xavier