Other Parts Discussed in Thread: TPS65916
Hi Experts,
Our customer was developing their system with AM5716, and they are producing more than 100 units, however, customer encountered the freeze-issue recently. It seems this issue occurred on just only one board. The phenomenon of this issue and what customer analyzed are as follows. From the following information, customer supposes that it’s an individual defect. However, customer would like to know TI’s comments on this issue. Also, they are asking if it is possible to guess the root cause of this issue because customer's mass production is soon. would you have heard similar issue report so far?
I believe It is tough to consider this root cause, can I have your expert’s advice/comments on this customer’s inquiry, please?
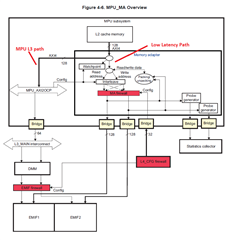
- MMC2_CLK (# J7 pin) suddenly stops while accessing the eMMC that connected to the MMC2 block. ( Rarely occurs )
- It seems to be easy to reproduce this issue when data is transferred for relatively large file sizes (300MB-500MB)
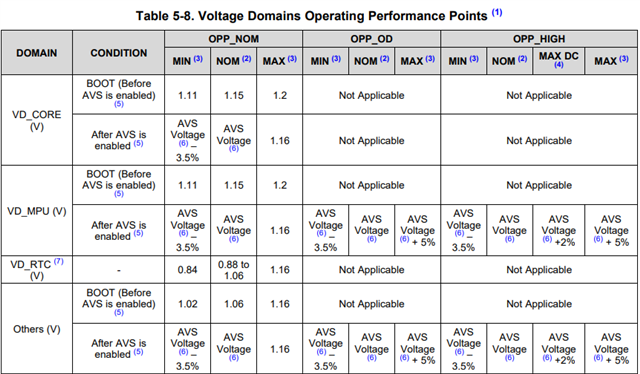
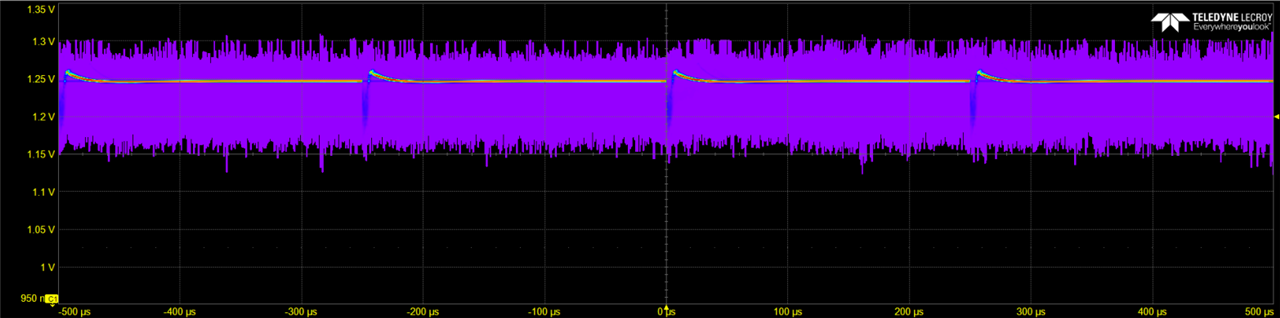
- Customer has checked all power supply rails, reset and clocks are also connected correctly, and they confirmed there was not any problem.
- Customer tried to connect LAUTERBACH’s JTAG emulator to AM5716, but JTAG also crashed after a problem occurred. It means, it’s Unanalyzable.
- It seems that not only MMC2_CLK stopped suddenly , but also the entire AM5716 seemed to be freeze
- Customer checked the soldering condition with X-ray, there was no problem.
- When customer replaced this AM5716 with a new one, the problem no longer occurred.
It will be appreciated if you will share your comments on this.
Best regards,
Miyazaki