


SDK Version: 7.1 & 8.2
Import Config:
modelType = 2
inputNetFile = add1conv.onnx
outputNetFile = test_yuv/detection.bin
outputParamsFile = test_yuv/detection_cfg.bin
numParamBits = 8
quantizationStyle = 3
inElementType = 0
inWidth = 640
inHeight = 384
inNumChannels = 1
inDataNorm = 1
inMean = 0 0 0
inScale = 0.00392156862745098 0.00392156862745098 0.00392156862745098
inDataFormat = 1
inResizeType = 0
resizeWidth = 640
resizeHeight = 384
perfSimTool = ./bin/perfsim/ti_cnnperfsim.out
perfSimConfig = ./bin/perfsim/device_config.cfg
graphVizTool = ./bin/tidl_graphVisualiser.out
tidlStatsTool = ./bin/PC_dsp_test_dl_algo.out
inData = /home/omagiclee/Documents/projects/tda4/import_tool_sdk8.2/images_yuv/640_384.yuv
postProcType = 2
debugTrace = 1
debugTraceLevel = 2
writeTraceLevel = 3
foldBnInConv2D = 0
foldPreBnConv2D = 0
inYuvFormat = 0
inFileFormat = 1
rawDataInElementType = 0
numFrames = 1
Hi, All:
We set the inYuvFormat para true when importing onnx model to .bin model. However the accuracy of the final .bin model decreases a lot.
To analysis the problem, we set the foldBn para false, debug the featmap layer by layer and find the following confusion:
(1) the graphes of models are : left if our original model (with foldBN false); right is our YUV input model with the same net arch as our original model.

we visualize the featmaps layer by layer and find that:
(a) the ColorConversion output may by wrong. The left matrix is a subset of UVUV which is the input of the ColorConversion layer and the middle matrix and the right matrix are the U and V matrix of the output of the ColorConversion layer. As the input format of YUV is NV12, we find the pink number is wrong and the U and V value is exchanged. and some other lines is also with the same problem

(b) the 1x1 Conv2D to do the transformation from yuv to rgb may be wrong. We find that the input of Convolution[4, 4] is YUV(with shape of (384x640x3)) while the output of it is YYY(with the shape of (384x640x3)) rather than expected RGB image.
2. Besides, we following the advise from Desay and Ti, wo explicitly add a identity 1x1 Conv2D after the input layer in the original network and it doesn't work either.
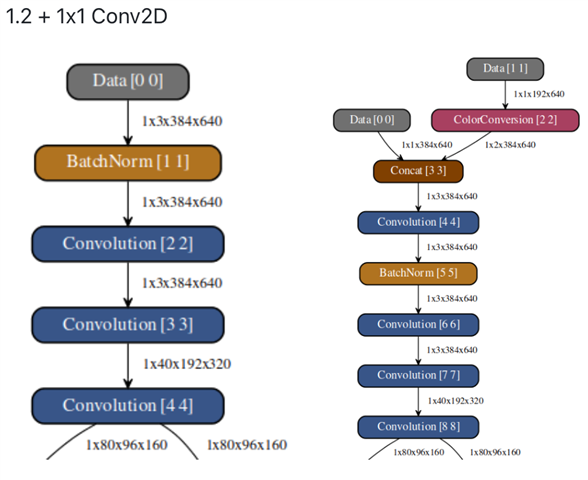
Are we wrong about the process of the YUV to RGB, and how can we achieve the goal (with YUV NV12 input, the accuracy do not decrease as the transformation from yuv to rgb is fixed)?