Hello,
I have a question considering QAT.
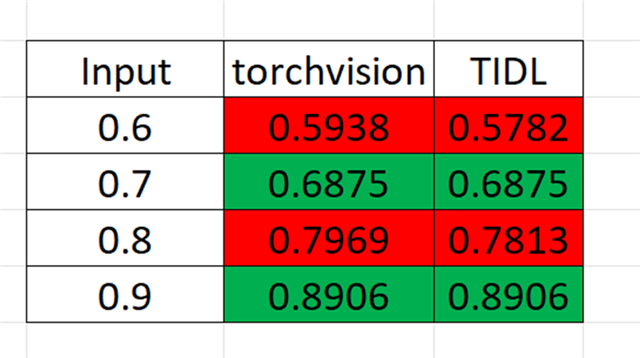
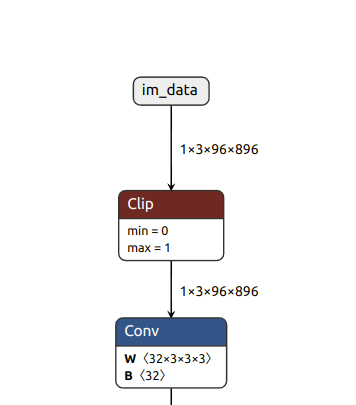
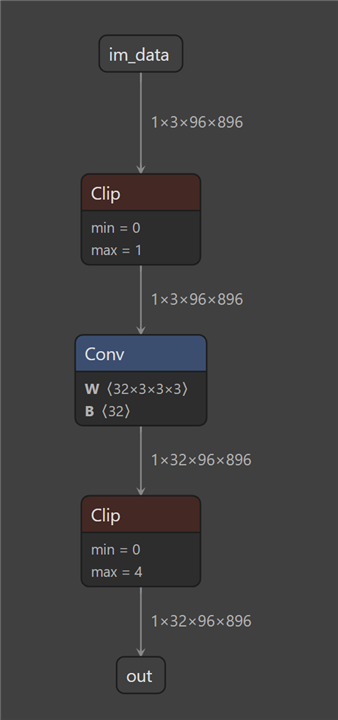
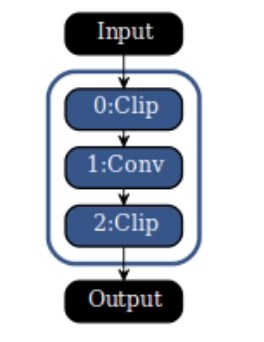
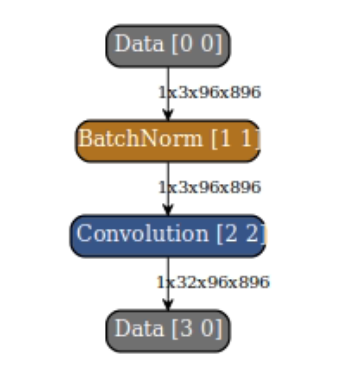
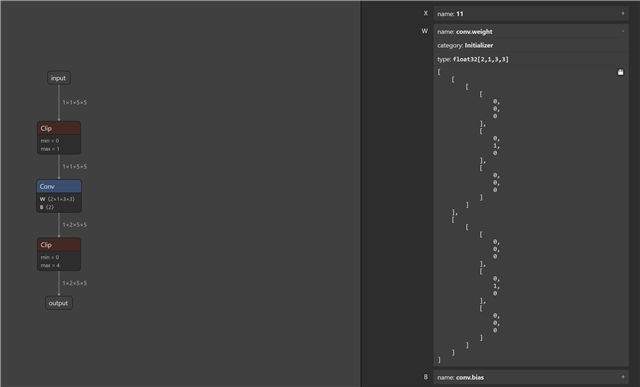
I would like to perform 8 bit quantization for some model layers and inference some layers with 16 bits precision. I made some changes in the edgai-torchvision so that those layers (convolutional) will not be replaced
with the QuantTrainConv2d and also they will not receive the PACT2. Those layers will not "receive" the Clip layer in the ONNX graph.
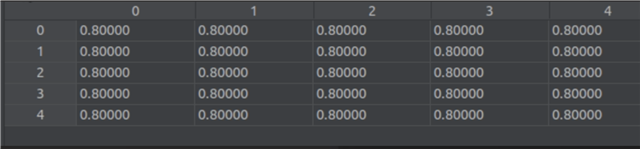
Now I would like to perform compilation and create artifacts in the TIDL. I don't want to change the already computed clip ranges for the 8 bit layers. but I would like to compute those for the "untouched" ones for 16 bit range. How can this be done?
Thank you,
Alex.



 '
'