


Other Parts Discussed in Thread: TDA4VH,
Model: int16-tmp.onnx
1. Model Importer Operation
shell command : ./tidl_model_import.out tidl_import_cfg.txt
2. Model Inference Operation
Environment: TDA4VM and TDA4VH with sdk 8.5.0
Compared with the VM version(j721e-evm-08_05_00_11), Inference performance of the model degrades for VH version.
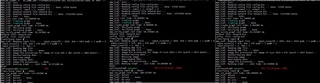
Execute the test_tidl test case, count the execution time of vxProcessGraph, and find that the performance of the VH version is degraded (VM: 15.571ms; VH: 18.524ms);
Enable C7x L2Cache in TDA4VH, set it to 64KB, re-execute the test case, the execution time is 16.895ms, the performance has improved, but it is still worse than the VM version.
The results are shown in the picture below.
Please refer to the attachment int16-tmp.rar for more details about the configuration, model and test case. int16-tmp.rar
