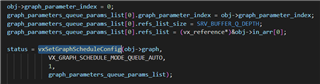
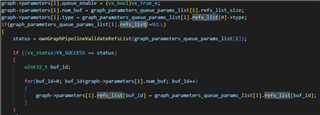
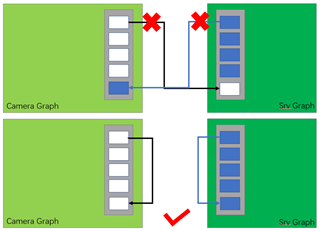
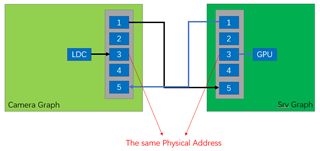
Hi Ti's Experts,
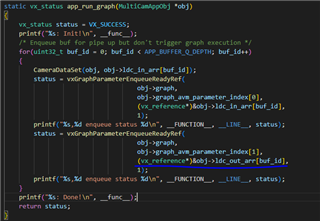
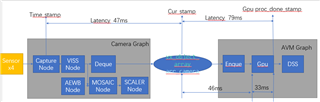
We made the software of surroud view on Tda4, Using the Hardware GPU、 CAMERA、 VPAC(VISS, AEWB,MSC)、DSS.
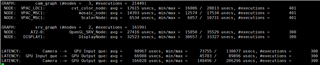
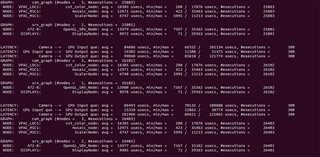
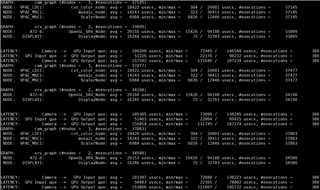
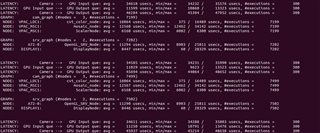
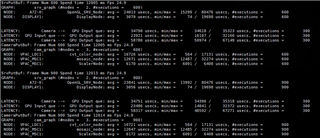
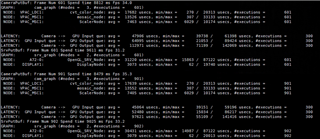
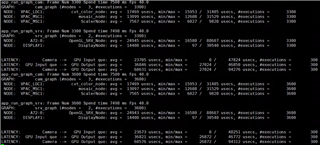
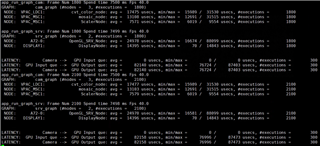
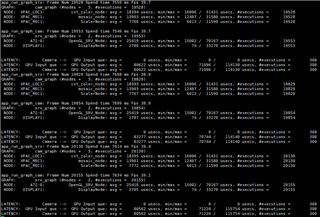
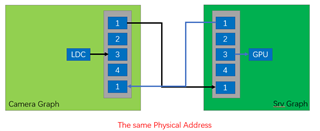
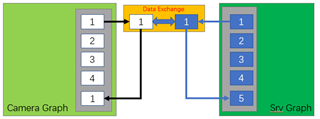
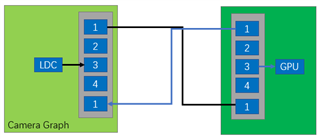
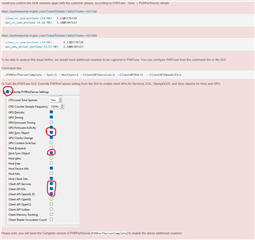
GRAPH 1 GRAPH2
Buffer_size:4 pipeline depth:8 Buffer_size:3 pipeline Depth:3
CAMERA(4 Pcs) ---> WISS ---> AEWB---> MSC GPU--->DSS
FPS:30 FPS:30
DELAY:47.2ms DELAY:76.9ms
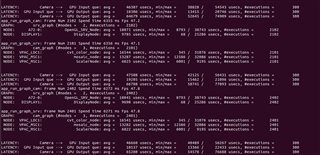
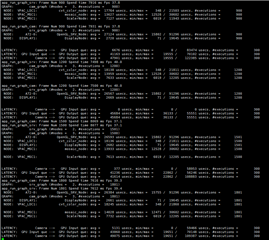
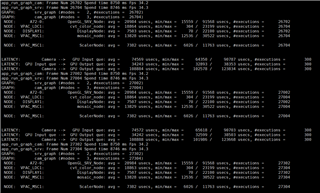
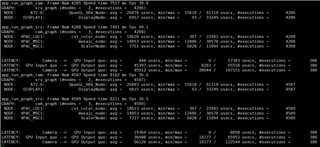
The time consumption of each node is as follows:


We want to reduce the delay while maintaining the frame rate .So, Shall your share some suggestions for us?
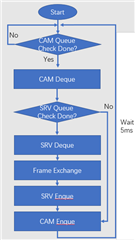
We also tried some methods:
1. Set SRV(GRAPH2) Buffer_size to 2, pipeline Depth to 2: the DELAY can reduce about 40ms, but FPS also reduced to 15FPS
2. Set CAMERA (GRAPH1) Buffer_size to 3, the FPS CAMERA reduced to 25Fps.
3. Change SRV or CAMERA pipeline depth, it seem no impact.
So We have some questions, please help to answer:
1. What is the effect of changing The pipeline depth, and how will it be improved by increasing or decreasing The pipeline depth?
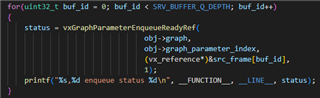
2. The actual processing time of GPU is 33ms . Why is there more than 70ms delays on SRV graph.
3. Is there a good way to keep the frame rate and reduce the delay?
Thanks a lot, Look for your reply!