Environment:
- TI Edge AI Cloud (which connects to a TDA4VM board).
- Ubuntu20.04, PROCESSOR-SDK-RTOS-J721S2, 08.00.04.04, for TDA4VL.
- Ubuntu20.04, PROCESSOR-SDK-RTOS-J784S4, 08.02.02.02, for TDA4VH.
We tried the three above environments separately and got the same problem below.
Model:
- MobileNetV2 + 1fc layer.
- Inputs are size 96x96x3 images, uint8. Pixels are normalized to [-1,1] in training process, i.e., y=(x-127.5)/127.5
- Outputs are angles in [0,180] range
- The float tflite model runs well and we got expected outputs in the range [0,180] for any input images.
- Layers are supported by TIDL. Same architecture was used for 0-1 classification and can be converted and run without issue.
Problem Description:
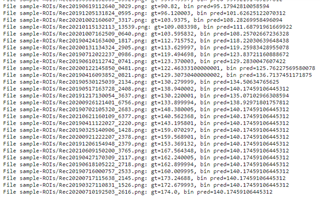
We are generating 16-bit model binaries from a well trained tflite file for TDA4VH. Calibration data include 119 images with ground truth covering the range [0, 180]. Testing data include 60 images with ground truth covering the same range. Testing is run in emulation mode on PC. The configuration for importer and inference look like below.

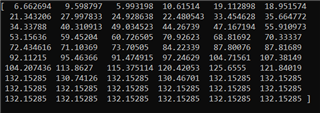
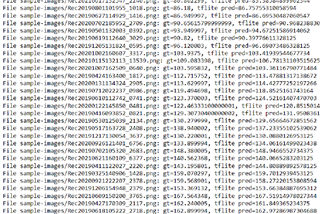
The 16bit binaries can be generated without any issue. When evaluated the performance, we found that the outputs are cut-off at around 132. In other words, it works well on any images with groud truth <132. For input iamges with groud truth>132, it output fixed values like 132.1528. Seems like the value got overflow somewhere. Output predictions look like below.
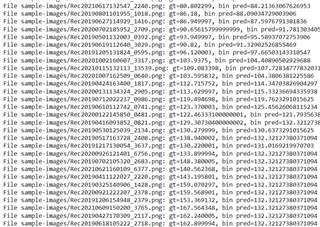
We then uploaded the float tflite model and images to TI Edge Cloud to generate model binaries, and found it has exactly the same problem, like below,
We then tested it with TIDL importer under the SDK TDA4VL, same again. Our float tflite model does not have this problem. Below is the output from our float tflite model, everything is good.
What would be a solution to this problem? Thanks.
Hello Paula Carrillo , I am looking for techinical help. Could you reivew my problem described above and if possible give any potential solutions? Our team need this to be solved ASAP. Please let me know if I need to provide more details for you to investigate. Thanks.