Hi,
We are trying to test segmentation model conversion for the developer board of tda4vm. We are facing some issues with model conversion, especially semantic segmentation.
Our goal is to convert one of the semantic segmentation models provided by Texas instruments and run it on the target.
For this we followed the following steps,
First we checked some of the models that were provided by TI.
We downloaded deeplabv3plus_mobilenet_v2_edgeai_lite from this link. The onnx model link.
We were able to convert this model in rtos SDK 8.0 and rtos SDK 8.5( also using corresponding edgeai-tidl-tools repo(8.5))
Now we are trying to convert the torch model to onnx and then onnx to TIDL model. For this, we use the recommended version of torchvision from texas instruments github repo. https://github.com/TexasInstruments/edgeai-torchvision/tree/master We build it using a Dockerfile.

We used this to convert the same deeplabv3plus_mobilenetv2_edgeai_lite model. We were able to conver this model from torch to onnx. We were also able to load the weights of the trained model(link).
When we try to convert this onnx model to TIDL model, we have the following problems
In SDK 8.0 version -> We get a segmentation fault error. After putting debug_level to more than 3, we don't get much information
python deeplab_onnx_to_tidl.py 0.0s: VX_ZONE_INIT:Enabled 0.22s: VX_ZONE_ERROR:Enabled 0.24s: VX_ZONE_WARNING:Enabled tidl_tools_path = /fastdata/niranjan/j721e/sdk_files/ti-processor-sdk-rtos-j721e-evm-08_00_00_12/tidl_j7_08_00_00_10/tidl_tools artifacts_folder = ./deeplabv3plus_mobilenet_v2_tv/ tidl_tensor_bits = 8 debug_level = 10 num_tidl_subgraphs = 16 tidl_denylist = tidl_calibration_accuracy_level = 64 tidl_calibration_options:num_frames_calibration = 1 tidl_calibration_options:bias_calibration_iterations = 1 power_of_2_quantization = 2 enable_high_resolution_optimization = 0 pre_batchnorm_fold = 0 add_data_convert_ops = 0 output_feature_16bit_names_list = m_params_16bit_names_list = reserved_compile_constraints_flag = 1601 ti_internal_reserved_1 = Parsing ONNX Model model_proto 0x7fff99a71db0 Supported TIDL layer type --- Clip -- Clip_0 Supported TIDL layer type --- Conv -- Conv_1 Supported TIDL layer type --- Clip -- Clip_2 Supported TIDL layer type --- BatchNormalization -- BatchNormalization_3 Supported TIDL layer type --- Clip -- Clip_4 Supported TIDL layer type --- Conv -- Conv_5 Supported TIDL layer type --- Clip -- Clip_6 Supported TIDL layer type --- Conv -- Conv_7 Supported TIDL layer type --- Clip -- Clip_8 Supported TIDL layer type --- Conv -- Conv_9 Supported TIDL layer type --- Clip -- Clip_10 Supported TIDL layer type --- Conv -- Conv_11 Supported TIDL layer type --- Clip -- Clip_12 Supported TIDL layer type --- Conv -- Conv_13 Supported TIDL layer type --- Clip -- Clip_14 Supported TIDL layer type --- Conv -- Conv_15 Supported TIDL layer type --- Clip -- Clip_16 Supported TIDL layer type --- Conv -- Conv_17 Supported TIDL layer type --- Clip -- Clip_18 Supported TIDL layer type --- Conv -- Conv_19 Supported TIDL layer type --- Clip -- Clip_20 [1] 2197650 segmentation fault (core dumped) python deeplab_onnx_to_tidl.py
In sdk 8.5 -> We are able to compile the onnx model into TIDL format. However, it breaks up the model into multiple smaller graphs
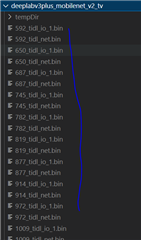
However, if the onnx model from the official link is used, no sub graphs/models are created.
Could you let us know where we are going wrong in our steps. Is this the workflow you intended for model conversion or is it something else?
Thank You
Niranjan