Issue: Inference thread crashes during the model inference process.
We suspect that it may be due to insufficient resources, but no effective logs have been observed.
Details:
The CPU usage remains consistently high (97%), and we are working on optimization.
The shared memory usage is approximately 80MB, which should be within the configured limit of 512MB.
The average memory bandwidth is around 5.5GB/s with a peak of 104GB/s.
Hardware: tda4vm
ti_sdk Version: ti sdk 8.4
Trigger Condition: Simultaneous inference of 7 models using 4 threads, with one of the models being larger. If we remove this largest model, we haven't encountered any crashes for now.
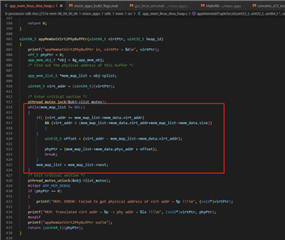
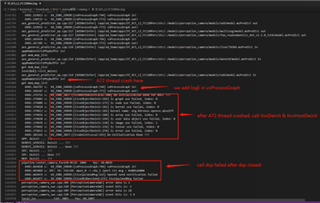
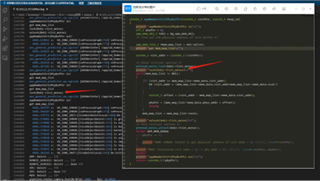
By adding logs in the tiovx source code, we have identified the crash location as follows. During multiple tests, the crashes occur between 10 to 90 minutes, and the crash position remains consistent.