Part Number: TDA4VM
Other Parts Discussed in Thread: DRA829,
Hi,TI
1. Do all Ramids support inject only? When ECC self-test, use "ECC_ENABLE = 1, ECC_CHECK=0" to open ECC for fault injection self-test?
I tried to enable ECC in the above way, turned off the ECC after the self-check, and then enabled ECC after the fault was cleared.
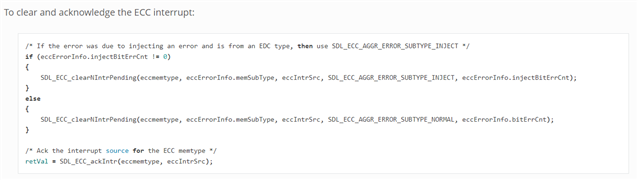
When the ESM associates with errpin, the errpin is pulled down by an unrecoverable fault of the ECC_MEMTYPE_MCU_CBASS_ECC_AGGR0 module.
The fault in the self-test should not be cleared.
In SDL, module like ECC_MEMTYPE_MCU_CBASS_ECC_AGGR0, there is no RamId that can be read directly in memory, should not involve Ram initialization,
and address content write back, is there any other way to clear self-check fault?
2. From SDL, the group of the following ramids is 0. How to do ECC self-check on these ramids?

3. MCU_NAVSS0_UDMASS_ECC_AGGR0_NAVSS_MCU_J7_UDMASS_PSILSS0_L2P_NAVSS_PSIL_EDC_CTRL_0_RAM_ID:
Why does this RamId report a 2bit fault after ECC initialization (no injection fault)?
4. Why does the following module or ramId not receive ESM_STS and ESM_RAW register responses after injection failure?
PSRAMECC0_PSRAM256X32EC_ECC_AGGR
PSRAMECC0_PSRAM256X32EC_ECC_AGGR_PSRAM256X32E_16FFC_PSRAM0_ECC_RAM_IDECC
R5FSS0_CORE1_ECC_AGGR (about iCatch dCatch TCM)
R5FSS1_CORE1_ECC_AGGR (about iCatch dCatch TCM)
5. The following three modules involve high address mapping.
COMPUTE_CLUSTER0_A72SS0_COMMON_ECC_AGGR
COMPUTE_CLUSTER0_A72SS0_CORE0_ECC_AGGR
COMPUTE_CLUSTER0_A72SS0_CORE1_ECC_AGGR
1) After the mapping is complete, the COMMON_ECC module can access the mapped aggregator address to inject the fault, interconnect type ramId self-check can pass; wrapper type self-check does not pass, why ESM_STS and ESM_RAW registers do not receive fault response after fault injection?
2) Why do two modules CORE0_ECC and CORE1_ECC get stuck when accessing the mapped address?
6. CBASS_ECC_AGGR0_MSRAM32KX256E_ECC_AGGR
In SDL, why is the base address of the ECC AGGR corresponding to this module 0, and there is no ESM EventId? How to do eccc self-check on this module?
Thanks,
Yanni