Part Number: AM6442
Other Parts Discussed in Thread: SYSCONFIG
We are witnessing spurious Hardware Faults on one of the R5F cores which is also accessing the external DDR4 memory for both code & data. Our board is a proprietary design.
I have a incident of Prefetch Abort fault which I want to debug deeper; with the help of application note "sprad28". I would appreciate your confirmation.
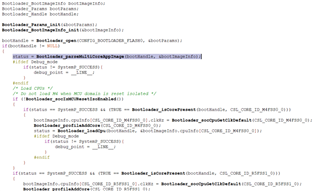
I am loading the multicore project via CCS and leave it to run. After a while the core R5_0_1 hangs while the other cores keep running. When pausing the CCS session, I can see that core R5_0_1 is caught in Prefetch Abort handler :

The core registers are as follows :
CPSR register M[4..0] is 10111 meaning currently in Abort mode.

SPSR register M[4..0] is 11111 meaning that the processor was previously in System mode.


So : it's understood that we went from System mode to Abort mode.

The Core register R14 is actually 0x00000001 : can I deduct anything from this value? It doesn't look like a proper address where code may reside...

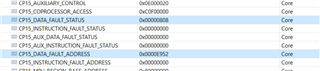
From the System registers in CCS

It looks like the prefetch abort is caused by a Instruction Fault and the IFSR Instruction Fault Status Register there is 0x0000000D. From ARM website I deduct that this would be an MMU Permission Fault : https://developer.arm.com/documentation/ddi0406/c/System-Level-Architecture/Virtual-Memory-System-Architecture--VMSA-/Exception-reporting-in-a-VMSA-implementation/Fault-reporting-in-PL1-modes?lang=en#CBHHADIB

The Instruction Fault Address Register IFAR is 0x0107A9D4 which doesn't make sense at all to me. It doesn't look like a valid address in the MAIN domain and we don't use RAT (Region Address Translation) on this core. The TRM has nothing mapped on this address :

Are my assumptions correct so far?
Going back to Core register R13 (Stack Pointer); here I see the value 0x70114D78. Comparing against my symbol table for this core :
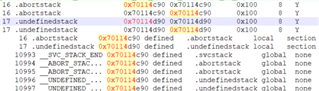
is it possible that I'm running out of stack space? We have already tried increasing the Stack Size earlier, but maybe we didn't try hard enough...
I would appreciate your feedback on this debug session. Please let me know if you need more info; but I cannot always reproduce the issue at hand.
kind regards,
Marc