Hello experts,
My SDK version is processor-sdk-linux-sk-tda4vm-08_04_00.I want to train semantic segmentation model. I download the edgeai--torchvision-master.
My operation is as follows:
(edgeai-tv) root@zhouxin:/home/machunlei/codes/edgeai-torchvision-master# python ./references/edgeailite/main/pixel2pixel/train_segmentation_main.py --model_name deeplabv3plus_mobilenetv2_tv_edgeailite --dataset_name cityscapes_segmentation --data_path ../datasets/cityscapes --img_resize 384 768 --output_size 1024 2048 --pretrained download.pytorch.org/.../mobilenet_v2-b0353104.pth --gpus 0 1
/home/machunlei/codes/edgeai-torchvision-master/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: ''If you don't plan on using image functionality from `torchvision.io`, you can ignore this warning. Otherwise, there might be something wrong with your environment. Did you have `libjpeg` or `libpng` installed before building `torchvision` from source?
warn(
/home/machunlei/codes/edgeai-torchvision-master/torchvision/__init__.py:25: UserWarning: You are importing torchvision within its own root folder (/home/machunlei/codes/edgeai-torchvision-master). This is not expected to work and may give errors. Please exit the torchvision project source and relaunch your python interpreter.
warnings.warn(message.format(os.getcwd()))
=> args: {'dataset_config': {'split_name': 'val', 'max_depth_bfr_scaling': 80, 'depth_scale': 1, 'train_depth_log': 1}, 'use_semseg_for_depth': False, 'model_config': {'output_type': ['segmentation'], 'output_channels': None, 'prediction_channels': None, 'input_channels': (3,), 'final_upsample': True, 'output_range': None, 'num_decoders': None, 'freeze_encoder': False, 'freeze_decoder': False, 'multi_task_type': 'learned', 'target_input_ratio': 1, 'input_nv12': False, 'enable_fp16': False}, 'model': None, 'model_name': 'deeplabv3plus_mobilenetv2_tv_edgeailite', 'dataset_name': 'cityscapes_segmentation', 'transforms': None, 'input_channel_reverse': False, 'annotation_prefix': 'instances', 'data_path': '../datasets/cityscapes', 'save_path': None, 'phase': 'training', 'date': '2023-08-25_14-56-02', 'output_dir': None, 'logger': <edgeai_xvision.xnn.utils.logger.TeeLogger object at 0x7f3d0c3bdc00>, 'show_gpu_usage': False, 'device': None, 'distributed': False, 'split_file': None, 'split_files': None, 'split_value': None, 'optimizer': 'adam', 'scheduler': 'step', 'workers': 8, 'epochs': 1, 'start_epoch': 0, 'epoch_size': 0, 'epoch_size_val': 0, 'batch_size': 12, 'total_batch_size': 12, 'iter_size': 1, 'lr': 0.0004, 'lr_clips': None, 'lr_calib': 0.05, 'warmup_epochs': 5, 'warmup_factor': 0.001, 'momentum': 0.9, 'beta': 0.999, 'weight_decay': 0.0001, 'bias_decay': None, 'sparse': True, 'tensorboard_num_imgs': 5, 'pretrained': 'download.pytorch.org/.../mobilenet_v2-b0353104.pth', 'resume': None, 'no_date': False, 'print_freq': 10, 'milestones': (100, 200), 'losses': [['segmentation_loss']], 'metrics': [['segmentation_metrics']], 'multi_task_factors': None, 'class_weights': None, 'loss_mult_factors': None, 'multistep_gamma': 0.25, 'polystep_power': 0.9, 'rand_seed': 1, 'img_border_crop': None, 'target_mask': None, 'rand_resize': [384, 768], 'rand_output_size': None, 'rand_scale': (1.0, 2.0), 'rand_crop': [384, 768], 'img_resize': [384, 768], 'output_size': [1024, 2048], 'count_flops': True, 'shuffle': True, 'shuffle_val': True, 'transform_rotation': 5, 'is_flow': None, 'upsample_mode': 'bilinear', 'image_prenorm': True, 'image_mean': (128.0,), 'image_scale': (0.015625,), 'max_depth': 80, 'pivot_task_idx': 0, 'parallel_model': True, 'parallel_criterion': True, 'evaluate_start': True, 'save_onnx': True, 'print_model': False, 'run_soon': True, 'quantize': False, 'bitwidth_weights': 8, 'bitwidth_activations': 8, 'histogram_range': True, 'bias_calibration': True, 'per_channel_q': False, 'constrain_bias': None, 'save_mod_files': False, 'make_score_zero_mean': False, 'no_q_for_dws_layer_idx': 0, 'viz_colormap': 'rainbow', 'freeze_bn': False, 'tensorboard_enable': True, 'print_train_class_iou': False, 'print_val_class_iou': False, 'freeze_layers': None, 'opset_version': 11, 'prob_color_to_gray': (0.0, 0.0), 'interpolation': None, 'gpus': ['0', '1'], 'use_pinned_memory': False, 'n_iter': 0, 'best_metric': -1}
annotation_prefix: instances
batch_size: 12
best_metric: -1
beta: 0.999
bias_calibration: True
bias_decay: None
bitwidth_activations: 8
bitwidth_weights: 8
class_weights: None
constrain_bias: None
count_flops: True
data_path: ../datasets/cityscapes
dataset_config: {'split_name': 'val', 'max_depth_bfr_scaling': 80, 'depth_scale': 1, 'train_depth_log': 1}
dataset_name: cityscapes_segmentation
date: 2023-08-25_14-56-02
device: None
distributed: False
epoch_size: 0
epoch_size_val: 0
epochs: 1
evaluate_start: True
freeze_bn: False
freeze_layers: None
gpus: ['0', '1']
histogram_range: True
image_mean: (128.0,)
image_prenorm: True
image_scale: (0.015625,)
img_border_crop: None
img_resize: [384, 768]
input_channel_reverse: False
interpolation: None
is_flow: None
iter_size: 1
logger: <edgeai_xvision.xnn.utils.logger.TeeLogger object at 0x7f3d0c3bdc00>
loss_mult_factors: None
losses: [['segmentation_loss']]
lr: 0.0004
lr_calib: 0.05
lr_clips: None
make_score_zero_mean: False
max_depth: 80
metrics: [['segmentation_metrics']]
milestones: (100, 200)
model: None
model_config: {'output_type': ['segmentation'], 'output_channels': None, 'prediction_channels': None, 'input_channels': (3,), 'final_upsample': True, 'output_range': None, 'num_decoders': None, 'freeze_encoder': False, 'freeze_decoder': False, 'multi_task_type': 'learned', 'target_input_ratio': 1, 'input_nv12': False, 'enable_fp16': False}
model_name: deeplabv3plus_mobilenetv2_tv_edgeailite
momentum: 0.9
multi_task_factors: None
multistep_gamma: 0.25
n_iter: 0
no_date: False
no_q_for_dws_layer_idx: 0
opset_version: 11
optimizer: adam
output_dir: None
output_size: [1024, 2048]
parallel_criterion: True
parallel_model: True
per_channel_q: False
phase: training
pivot_task_idx: 0
polystep_power: 0.9
pretrained: download.pytorch.org/.../mobilenet_v2-b0353104.pth
print_freq: 10
print_model: False
print_train_class_iou: False
print_val_class_iou: False
prob_color_to_gray: (0.0, 0.0)
quantize: False
rand_crop: [384, 768]
rand_output_size: None
rand_resize: [384, 768]
rand_scale: (1.0, 2.0)
rand_seed: 1
resume: None
run_soon: True
save_mod_files: False
save_onnx: True
save_path: None
scheduler: step
show_gpu_usage: False
shuffle: True
shuffle_val: True
sparse: True
split_file: None
split_files: None
split_value: None
start_epoch: 0
target_mask: None
tensorboard_enable: True
tensorboard_num_imgs: 5
total_batch_size: 12
transform_rotation: 5
transforms: None
upsample_mode: bilinear
use_pinned_memory: False
use_semseg_for_depth: False
viz_colormap: rainbow
warmup_epochs: 5
warmup_factor: 0.001
weight_decay: 0.0001
workers: 8
=> will save everything to ./data/checkpoints/edgeailite/cityscapes_segmentation/2023-08-25_14-56-02_cityscapes_segmentation_deeplabv3plus_mobilenetv2_tv_edgeailite_resize768x384_traincrop768x384/training
=> fetching images in '../datasets/cityscapes'
=> 3475 samples found, 2975 train samples and 500 test samples
=> class weights available for dataset: [array([0.056, 0.323, 0.09 , 1.036, 1.034, 1.682, 5.585, 3.566, 0.127,
1. , 0.468, 1.346, 5.3 , 0.283, 0.94 , 0.816, 0.427, 3.64 ,
2.784])]
Using downloaded and verified file: ./data/downloads/mobilenet_v2-b0353104.pth
=> loading pretrained weights file: download.pytorch.org/.../mobilenet_v2-b0353104.pth
=> creating model 'deeplabv3plus_mobilenetv2_tv_edgeailite'
=> using pretrained weights from: download.pytorch.org/.../mobilenet_v2-b0353104.pth
=> The following layers in the model could not be loaded from pre-trained:
decoders.0.aspp.conv1x1.0.weight
decoders.0.aspp.conv1x1.1.weight
decoders.0.aspp.conv1x1.1.bias
decoders.0.aspp.conv1x1.1.running_mean
decoders.0.aspp.conv1x1.1.running_var
decoders.0.aspp.aspp_bra1.0.0.weight
decoders.0.aspp.aspp_bra1.0.1.weight
decoders.0.aspp.aspp_bra1.0.1.bias
decoders.0.aspp.aspp_bra1.0.1.running_mean
decoders.0.aspp.aspp_bra1.0.1.running_var
decoders.0.aspp.aspp_bra1.1.0.weight
decoders.0.aspp.aspp_bra1.1.1.weight
decoders.0.aspp.aspp_bra1.1.1.bias
decoders.0.aspp.aspp_bra1.1.1.running_mean
decoders.0.aspp.aspp_bra1.1.1.running_var
decoders.0.aspp.aspp_bra2.0.0.weight
decoders.0.aspp.aspp_bra2.0.1.weight
decoders.0.aspp.aspp_bra2.0.1.bias
decoders.0.aspp.aspp_bra2.0.1.running_mean
decoders.0.aspp.aspp_bra2.0.1.running_var
decoders.0.aspp.aspp_bra2.1.0.weight
decoders.0.aspp.aspp_bra2.1.1.weight
decoders.0.aspp.aspp_bra2.1.1.bias
decoders.0.aspp.aspp_bra2.1.1.running_mean
decoders.0.aspp.aspp_bra2.1.1.running_var
decoders.0.aspp.aspp_bra3.0.0.weight
decoders.0.aspp.aspp_bra3.0.1.weight
decoders.0.aspp.aspp_bra3.0.1.bias
decoders.0.aspp.aspp_bra3.0.1.running_mean
decoders.0.aspp.aspp_bra3.0.1.running_var
decoders.0.aspp.aspp_bra3.1.0.weight
decoders.0.aspp.aspp_bra3.1.1.weight
decoders.0.aspp.aspp_bra3.1.1.bias
decoders.0.aspp.aspp_bra3.1.1.running_mean
decoders.0.aspp.aspp_bra3.1.1.running_var
decoders.0.aspp.aspp_out.0.weight
decoders.0.aspp.aspp_out.1.weight
decoders.0.aspp.aspp_out.1.bias
decoders.0.aspp.aspp_out.1.running_mean
decoders.0.aspp.aspp_out.1.running_var
decoders.0.shortcut.0.weight
decoders.0.shortcut.1.weight
decoders.0.shortcut.1.bias
decoders.0.shortcut.1.running_mean
decoders.0.shortcut.1.running_var
decoders.0.pred.0.0.weight
decoders.0.pred.0.1.weight
decoders.0.pred.0.1.bias
decoders.0.pred.0.1.running_mean
decoders.0.pred.0.1.running_var
decoders.0.pred.1.0.weight
=> The following weights in pre-trained were not used:
encoder.features.18.0.weight
encoder.features.18.1.weight
encoder.features.18.1.bias
encoder.features.18.1.running_mean
encoder.features.18.1.running_var
classifier.1.weight
classifier.1.bias
====================================================================================================
Layer (type:depth-idx) Output Shape Param #
====================================================================================================
DeepLabV3PlusEdgeAILite [1, 1, 384, 768] --
├─MobileNetV2TVMI4: 1-1 [1, 320, 24, 48] --
│ └─Sequential: 2-1 -- --
│ │ └─Sequential: 3-1 [1, 32, 192, 384] 928
│ │ └─InvertedResidual: 3-2 [1, 16, 192, 384] 896
│ │ └─InvertedResidual: 3-3 [1, 24, 96, 192] 5,136
│ │ └─InvertedResidual: 3-4 [1, 24, 96, 192] 8,832
│ │ └─InvertedResidual: 3-5 [1, 32, 48, 96] 10,000
│ │ └─InvertedResidual: 3-6 [1, 32, 48, 96] 14,848
│ │ └─InvertedResidual: 3-7 [1, 32, 48, 96] 14,848
│ │ └─InvertedResidual: 3-8 [1, 64, 24, 48] 21,056
│ │ └─InvertedResidual: 3-9 [1, 64, 24, 48] 54,272
│ │ └─InvertedResidual: 3-10 [1, 64, 24, 48] 54,272
│ │ └─InvertedResidual: 3-11 [1, 64, 24, 48] 54,272
│ │ └─InvertedResidual: 3-12 [1, 96, 24, 48] 66,624
│ │ └─InvertedResidual: 3-13 [1, 96, 24, 48] 118,272
│ │ └─InvertedResidual: 3-14 [1, 96, 24, 48] 118,272
│ │ └─InvertedResidual: 3-15 [1, 160, 24, 48] 155,264
│ │ └─InvertedResidual: 3-16 [1, 160, 24, 48] 320,000
│ │ └─InvertedResidual: 3-17 [1, 160, 24, 48] 320,000
│ │ └─InvertedResidual: 3-18 [1, 320, 24, 48] 473,920
├─ModuleList: 1-2 --
│ └─DeepLabV3PlusEdgeAILiteDecoder: 2-2 [1, 1, 384, 768] --
│ │ └─Sequential: 3-19 [1, 48, 96, 192] 1,248
│ │ └─DWASPPLiteBlock: 3-20 [1, 256, 24, 48] 602,944
│ │ └─ResizeWith: 3-21 [1, 256, 96, 192] --
│ │ └─CatBlock: 3-22 [1, 304, 96, 192] --
│ │ └─Sequential: 3-23 [1, 19, 96, 192] 9,120
│ │ └─ResizeWith: 3-24 [1, 19, 384, 768] --
====================================================================================================
Total params: 2,425,024
Trainable params: 2,425,024
Non-trainable params: 0
Total mult-adds (G): 3.55
====================================================================================================
Input size (MB): 3.54
Forward/backward pass size (MB): 868.66
Params size (MB): 9.70
Estimated Total Size (MB): 881.90
====================================================================================================
=> Resize = [384, 768], GFLOPs = 7.090790144, GMACs = 3.545395072, MegaParams = 2.425024
============= Diagnostic Run torch.onnx.export version 2.0.1+cu118 =============
verbose: False, log level: Level.ERROR
======================= 0 NONE 0 NOTE 0 WARNING 0 ERROR ========================
=> setting adam optimizer
=> validation 100.00% of 1x42...Epoch=1/1, DataTime=0.2729, Output=[MeanIoU=0.4776] rate=0.27 Hz, eta=0:00:00, total=0:02:36
Traceback (most recent call last):
File "/home/machunlei/codes/edgeai-torchvision-master/./references/edgeailite/main/pixel2pixel/train_segmentation_main.py", line 278, in <module>
run(args)
File "/home/machunlei/codes/edgeai-torchvision-master/./references/edgeailite/main/pixel2pixel/train_segmentation_main.py", line 273, in run
main(arguments)
File "/home/machunlei/codes/edgeai-torchvision-master/./references/edgeailite/main/pixel2pixel/train_segmentation_main.py", line 123, in main
train_pixel2pixel.main(arguemnts)
File "/home/machunlei/codes/edgeai-torchvision-master/references/edgeailite/edgeai_xvision/xengine/train_pixel2pixel.py", line 614, in main
train(args, train_dataset, train_loader, model, optimizer, epoch, train_writer, scheduler, grad_scaler)
File "/home/machunlei/codes/edgeai-torchvision-master/references/edgeailite/edgeai_xvision/xengine/train_pixel2pixel.py", line 721, in train
for iter_id, (inputs, targets) in enumerate(train_loader):
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 633, in __next__
data = self._next_data()
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 1345, in _next_data
return self._process_data(data)
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 1371, in _process_data
data.reraise()
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/_utils.py", line 644, in reraise
raise exception
AssertionError: Caught AssertionError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/utils/data/_utils/worker.py", line 308, in _worker_loop
data = fetcher.fetch(index)
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py", line 51, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py", line 51, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/machunlei/codes/edgeai-torchvision-master/references/edgeailite/edgeai_xvision/xvision/datasets/cityscapes_plus.py", line 357, in __getitem__
assert this_image_path == image_path, 'image file name error'
AssertionError: image file name error
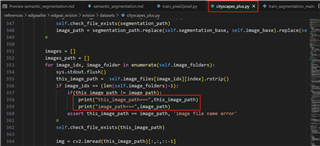
The bug is "this_image_path == image_path".There is something wrong with training. Why is the validation ok? So,I added print like this.
****
=> setting adam optimizer
=> validation 100.00% of 1x42...Epoch=1/1, DataTime=1.062, Output=[MeanIoU=0.4776] rate=0.22 Hz, eta=0:00:00, total=0:03:08
this_image_path===this_image_path=== ../datasets/cityscapes/leftImg8bit/train/zurich/zurich_000038_000019_leftImg8bit.png ../datasets/cityscapes/leftImg8bit/train/strasbourg/strasbourg_000001_017844_leftImg8bit.png
image_path=== image_path===../datasets/cityscapes/leftImg8bit/train/strasbourg/strasbourg_000001_018155_leftImg8bit.png
../datasets/cityscapes/leftImg8bit/train/zurich/zurich_000040_000019_leftImg8bit.png
this_image_path=== ../datasets/cityscapes/leftImg8bit/train/jena/jena_000055_000019_leftImg8bit.png
image_path=== ../datasets/cityscapes/leftImg8bit/train/jena/jena_000056_000019_leftImg8bit.png
this_image_path=== ../datasets/cityscapes/leftImg8bit/train/hanover/hanover_000000_004230_leftImg8bit.png
image_path=== ../datasets/cityscapes/leftImg8bit/train/hanover/hanover_000000_004646_leftImg8bit.png
this_image_path=== ../datasets/cityscapes/leftImg8bit/train/hamburg/hamburg_000000_091038_leftImg8bit.png
image_path=== ../datasets/cityscapes/leftImg8bit/train/hamburg/hamburg_000000_091155_leftImg8bit.png
this_image_path=== ../datasets/cityscapes/leftImg8bit/train/monchengladbach/monchengladbach_000000_011383_leftImg8bit.png
image_path=== ../datasets/cityscapes/leftImg8bit/train/monchengladbach/monchengladbach_000000_012376_leftImg8bit.png
this_image_path=== ../datasets/cityscapes/leftImg8bit/train/strasbourg/strasbourg_000001_065214_leftImg8bit.png
image_path=== ../datasets/cityscapes/leftImg8bit/train/strasbourg/strasbourg_000001_065572_leftImg8bit.png
Traceback (most recent call last):
File "/home/machunlei/codes/edgeai-torchvision-master/./references/edgeailite/main/pixel2pixel/train_segmentation_main.py", line 278, in <module>
run(args)
File "/home/machunlei/codes/edgeai-torchvision-master/./references/edgeailite/main/pixel2pixel/train_segmentation_main.py", line 273, in run
main(arguments)
File "/home/machunlei/codes/edgeai-torchvision-master/./references/edgeailite/main/pixel2pixel/train_segmentation_main.py", line 123, in main
train_pixel2pixel.main(arguemnts)
File "/home/machunlei/codes/edgeai-torchvision-master/references/edgeailite/edgeai_xvision/xengine/train_pixel2pixel.py", line 614, in main
train(args, train_dataset, train_loader, model, optimizer, epoch, train_writer, scheduler, grad_scaler)
File "/home/machunlei/codes/edgeai-torchvision-master/references/edgeailite/edgeai_xvision/xengine/train_pixel2pixel.py", line 721, in train
for iter_id, (inputs, targets) in enumerate(train_loader):
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 633, in __next__
data = self._next_data()
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 1345, in _next_data
return self._process_data(data)
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 1371, in _process_data
data.reraise()
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/_utils.py", line 644, in reraise
raise exception
AssertionError: Caught AssertionError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/utils/data/_utils/worker.py", line 308, in _worker_loop
data = fetcher.fetch(index)
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py", line 51, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/usr/local/anaconda3/envs/edgeai-tv/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py", line 51, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/machunlei/codes/edgeai-torchvision-master/references/edgeailite/edgeai_xvision/xvision/datasets/cityscapes_plus.py", line 360, in __getitem__
assert this_image_path == image_path, 'image file name error'
AssertionError: image file name error
this_image_path=== ../datasets/cityscapes/leftImg8bit/train/monchengladbach/monchengladbach_000000_019901_leftImg8bit.png
image_path=== ../datasets/cityscapes/leftImg8bit/train/monchengladbach/monchengladbach_000000_020303_leftImg8bit.png
(edgeai-tv) root@zhouxin:/home/machunlei/codes/edgeai-torchvision-master#