I am having problems with the compilation of a custom (Facial Landmark detection) model.
Both the onnx and the tflite version of the model are failing to compile.
They do however work perfectly, when I only do inference on the CPU.
More info about the model in question can be found here:
github.com/.../pj_tflite_face_landmark_with_attention
With tflite, the model compilation script stops with the following error:
tidl_import_common.cpp:192 void* my_alloc(int): Assertion 'ptr=NULL' failed
This is porbably due to the following messages:
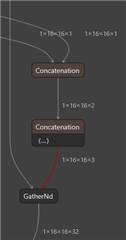
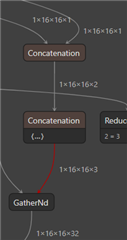
Unsupported (TIDL check) TIDL layer type --- 26 Tflite layer type --- 34 layer output name--- channel_padding
Unsupported (TIDL check) TIDL layer type --- 1 Tflite layer type --- 3 layer output name--- output_mesh_identity:0
Unsupported (TIDL check) TIDL layer type --- 0 Tflite layer type --- 0 layer output name--- Add_6
Unsupported (import) TIDL layer type for Tflite layer type --- 8 layer output name--- Floor
Unsupported (TIDL check) TIDL layer type --- 54 Tflite layer type --- 53 layer output name--- Cast
Unsupported (import) TIDL layer type for Tflite layer type --- 81 layer output name--- Prod
This is strange, because according to github.com/.../supported_ops_rts_versions.md Add and Conv2d layers should be supported.
When add these layers to the deny_list, the compilation script says:
'ALL MODEL CHECK PASSED'
and then during inference:
In TIDL_runtimesPostProccessNet 4
In TIDL_subgraphRtCreate
Bus error (core dumped)
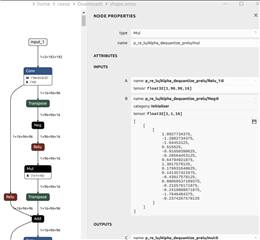
The onnx model has issues with the 'Neg' and 'Mul' layers. When I reduce the network to only the first few layers, the model still does not compile.
How can I fix this?
I have provided the models and compilation script.