Dear,
Sometimes our AM6548 based device could not boot from u-boot SPL to u-boot proper:
NOTICE: BL31: v2.6(release):NOTICE: BL31: Built : 08:03:39, Oct 20 2022I/TC:I/TC: OP-TEE version: 3.16.0 (gcc version 10.2.1 20210110 (Debian 10.2.1-6)) #1 Thu Oct 20 08:03:39 UTC 2022 aarch64I/TC: Primary CPU initializingI/TC: Primary CPU switching to normal world boot
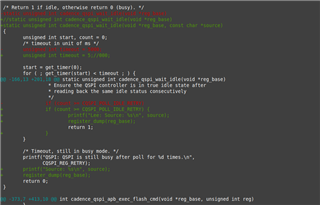
U-Boot SPL 2022.01-V01.03.01.01-0-gffc3caf (Oct 20 2022 - 08:10:44 +0000)SYSFW ABI: 3.1 (firmware rev 0x0015 '21.9.1--v2021.09a (Terrific Lla')Trying to boot from SPIQSPI: QSPI is still busy after poll for 10000 times.SPI probe failed.SPL: failed to boot from all boot devices
ERROR ### Please RESET the board
Any suggestions? Please see github.com/.../440 for details.