Part Number: AM6442
Other Parts Discussed in Thread: SYSCONFIG
Hello,
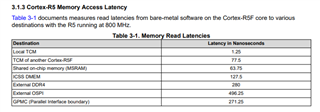
We are trying to switch from F28379D to a more performant AM64 platform. AM64 seems like a great option, but some measurements have surprised us. The same math computation takes:
- 280uS on Delfino with 200MHz clock and 2nd optimization;
- 215uS on R5F on AM64 with 800MHz clock and 3rd optimization;
- 30uS on A53 on AM64 with 1GHz clock and optimization 0.
We find the performance of R5 surprising. Is 200MHz Delfino supposed to perform almost the same as ARM R5f with 800MHz? Is there a way to improve the performance of the R5 core (optimization, enabling HW peripherals)?
Regards,
Andrean