We are building a system that includes an application that runs on an MCU island R5F (mcu1_1). This application runs every 15ms for about 10ms. During this runtime it exchanges data multiple times with another application that runs on the A72. This application has a realtime (sched_fifo) priority. The A72 is running Linux which includes the PREEMPT_RT patch set.
We planned to use rpmsg to implement the communication between these applications. (using ti-rpmsg-char on the A72) It does work and the communication time and general latency seem to be sufficient for our purposes. However, we have problems if a lower priority Linux task happens to run on the same core as the A72 application. If this lower priority task (f.e. some systemd housekeeping) runs for several miliseconds, receiving of data from the R5F is delayed by about that amount of time. We have made sure that the interrupt handlers that are involved have a sufficiently high priority, but that's not enough.
In traces, we can see that the normal flow for receiving data from the R5F for our A72 application in the system is this:
- mbox interrupt handler for mcu1_0 (mbox-mcu-r5fss0-core0) runs
- mbox interrupt handler for mxu1_1 (mbox-mcu-r5fss0-core1) runs
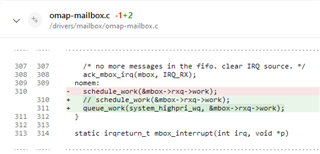
- kworker for this core runs
- our A72 application is awakened and receives the data
The problem is that the kworker thread has a normal priority (sched_other) and has to wait for other linux tasks, before it can start its work.
Are you aware of these kinds of problems? As far as we know, there is no easy way to change the default priority of these kworker threads in the Linux kernel. It is possible to change the priority of kworker threads that are currently running, but these threads are stopped and re-spawned regularly. Do you know of any Linux configuration options, which could skip the use of a kworker and directly complete everything during the interrupt handler? Do you have other suggestions for this problem? We'd like to avoid having to quarantine this core, in order not to waste CPU resources.